Given your probability of breaking the combo at each note, what is the probability distribution of your max combo in the rhythm game chart? I considered the problem seriously!
As a rhythm game player, I often wonder what my max combo will be in my next play. This is a rather unpredictable outcome, and what I can do is to try to conclude a probability distribution of my max combo.
For those who are not familiar with rhythm games and also to make the question clearer, I state the problem in a more mathematical setting.
Consider a random bit string of length n∈N, where each bit is independent and has probability Y∈[0,1] of being 1. Let Pn,k(Y) be the probability that the length of the longest all-1 substring of the bit string is k∈N (where obviously Pn,k(Y) is nonzero only when k≤n). What is the expression of Pn,k(Y)?
A more interesting problem to consider is what the probability distribution tends to be when n→∞. Define the random variable κ:=k/n where k is the length of the longest all-1 substring. Define a parameter y:=Yn (this parameter is held constant while n→∞). Define the probability distribution function of κ as f(y,κ):=n→∞lim(n+1)Pn,κn(yn1).(1) What is the expression of f(y,κ)?
Notation
Notation for integer range: a…b denotes the integer range defined by the ends a (inclusive) and b (exclusive), or in other words {a,a+1,…,b−1}. It is defined to be empty if a≥b. The operator … has a lower precedence than + and − but a higher precedence than ∈.
The notation a..b denotes the inclusive integer range {a,a+1,…,b}. It is defined to be empty if a>b.
The case for finite n
A natural approach to find Pn,k is to try to find a recurrence relation of Pn,k for different n and k, and then use a dynamic programming (DP) algorithm to compute Pn,k for any given n and k.
The first DP approach
For a rhythm game player, the most straightforward way of finding k for a given bit string is to track the current combo, and update the max combo when the current combo is greater than the previous max combo.
To give the current combo a formal definition, denote each bit in the bit string as bi, where i∈0…n. Define the current combo ri as the length of the longest all-1 substring of the bit string ending before (exclusive) i (so ri=0 if bi−1=0, which is callled a combo break):
ri:=max{r∈0..i∣∀j∈i−r…i:bj=1}, where i∈0..n.
Now, use three numbers (n,k,r) to define a DP state. Denote Pn,k,r to be the probability that the max combo is kand the final combo (rn) is r. Then, consider a transition from state (n,k,r) to state (n+1,k′,r′) by adding a new bit bn to the bit string. There are two cases:
If bn=0 (has 1−Y probability), then this means a combo break, so we have r′=0 and k′=k.
If bn=1 (has Y probability), then the combo continues, so we have r′=r+1. The max combo needs to be updated if needed, so we have k′=max(k,r′).
However, in actual implementation of the DP algorithm, we need to reverse this transition by considering what state can lead to the current state (n,k,r) (to use the bottom-up approach).
First, obviously in any possible case r∈0..k (currently we only consider the cases where n>k>0). Divide all those cases into three groups:
If r=0, this is means a combo break, so the last bit is 0, and the previous state can have any possible final combo r′. Therefore, it can be transitioned from any (n−1,k,r′) where r′∈0..k. For each possible previous state, the probability of the transition to this new state is 1−Y.
If r∈1..k−1, this means the last bit is 1, the previous final combo is r−1, and the previous max combo is already k. Therefore, the previous state is (n−1,k,r−1), and the probability of the transition is Y.
If r=k, this means the max combo may (or may not) have been updated. In either case, the previous final combo is r−1=k−1.
If the max combo is updated, the previous max combo must be k−1 because it must not be less than the previous final combo k−1 and must be less than the new max combo k. Therefore, the previous state is (n−1,k−1,k−1), and the probability of the transition is Y.
If the max combo is not updated, the previous max combo is the same as the new one, which is k. Therefore, the previous state is (n−1,k,k−1), and the probability of the transition is Y.
Therefore, we can write a recurrence relation that is valid when n>k>0: Pn,k,r=⎩⎨⎧(1−Y)∑r′=0kPn−1,k,r′,YPn−1,k,r−1,Y(Pn−1,k−1,k−1+Pn−1,k,k−1),r=0r∈1..k−1r=k.
However, there are also other cases (mostly edge cases) because we assumed n>k>0. Actually, in the meaningfulness condition n≥k≥r≥0 (necessary condition for Pn,k,r to be nonzero), there are three inequality that can be altered between a less-than sign or an equal sign, so there are totally 23=8 cases. Considering all those cases (omitted in this article because of the triviality), we can write a recurrence relation that is valid for all n,k,r, covering all the edge cases: Pn,k,r=⎩⎨⎧1,YPn−1,n−1,n−1,0,0,Y(Pn−1,k−1,k−1+Pn−1,k,k−1),YPn−1,k,r−1,(1−Y)∑r′=0kPn−1,k,r′,(1−Y)Pn−1,0,0,n=k=r=0,n=k=r>0,n=k>r>0,n=k>r=0,n>k=r>0,n>k>r>0,n>k>r=0,n>k=r=0.(2)
Note that the probabilities related to note count n only depend on those related to note count n−1 and that the probabilities related to max combo k and final combo r only depend on those related to either less max combo than k or less final combo than r (except for the case n>k>r=0, which can be specially treated before the current iteration of k actually starts), so for the bottom-up DP we can reduce the spatial complexity from O(n3) to O(n2) by reducing the 3-dimensional DP to a 2-dimensional one. What needs to be taken care of is that the DP table needs to be updated from larger k and r to smaller k and r instead of the other way so that the numbers in the last iteration in n are left untouched while we need to use them in the current iteration.
After the final iteration in n finishes, we need to sum over the index r to get the final answer: Pn,k=r=0∑kPn,k,r.
Writing the code for the DP algorithm is then straightforward. Here is an implementation in Ruby. In the code, dp[k][r] means Pn,k,r in the nth iteration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
## Returns an array of size m+1,## with the k-th element being the probability P_{m,k}.defcombom(1..m).each_with_object[[1]]do|n,dp|dp[n]=[0]*n+[Y*dp[n-1][n-1]]# n = k > 0(n-1).downto1do|k|# n > k > 0dpk0=(1-Y)*dp[k].sumdp[k][k]=Y*(dp[k-1][k-1]+dp[k][k-1])# n > k = r > 0(k-1).downto(1){|r|dp[k][r]=Y*dp[k][r-1]}# n > k > r > 0dp[k][0]=dpk0# n > k > r = 0enddp[0][0]*=1-Y# n > k = r = 0end.map&:sumend
Because of the three nested loops, the time complexity of the DP algorithm is O(n3).
The second DP approach
Here is an alternative way to use DP to solve the problem. Instead of building a DP table with the k,r indices, we can build a DP table with the n,k indices.
First, we need to rewrite the recurrence relation of Pn,k instead of that of Pn,k,r. We then need to try to express Pn,k,r in terms of Pn,k terms. The easiest part is the case where n≥k=r=0. By recursively applying Equation 2 to Pn,0,0, we have Pn,0,0=(1−Y)Pn−1,0,0=(1−Y)2Pn−2,0,0=⋯=(1−Y)nP0,0,0. Because P0,0,0=1, we have Pn,0,0=(1−Y)n.(3)
For n>k>r>0, we can recursively apply Equation 2 to get Pn,k,r=YPn−1,k,r−1=Y2Pn−2,k,r−2=⋯ This will finally either decend the note count to k or decend the final combo to 0, determined by which comes first.
If n−r≤k, we will decend to the term Pk,k,r−(n−k), which must be zero according to the case n=k>r=0 and the case n=k>r>0 in Equation 2, so Pn,k,r=0.
If n−r>k, then we will decend to the term Pn−r,k,0, which is equal to (1−Y)Pn−r−1,k according to the case n>k>r=0 in Equation 2.
Therefore, for n>k>r>0, we have Pn,k,r={0,Yr(1−Y)Pn−r−1,k,n−r≤k,n−r>k.(4)
For the case n>k=r>0, we can also recursively apply Equation 2 to get Pn,k,k=Y(Pn−1,k−1,k−1+Pn−1,k,k−1)=Y(Y(Pn−2,k−2,k−2+Pn−2,k−1,k−2)+Pn−1,k,k−1)=⋯=Y(Y(⋯Y(Pn−k,0,0+Pn−k,1,0)+⋯)+Pn−1,k,k−1)=YkPn−k,0,0+j=1∑kYjPn−j,k−j+1,k−j.
We can then substitute Equation 3 and 4 into the above equation. The substitution of Equation 3 can be done without a problem, but the substitution of Equation 4 requires some care because of the different cases.
If n−k>k, then only the case n−r>k in Equation 4 will be involved in the summation.
If n−k≤k, then both cases in Equation 4 will be involved in the summation. To be specific, for j∈1..2k−n+1, we need the case n−r≤k in Equation 4 (where the summed terms are just zero and can be omitted); for other terms in the summation, we need the other case.
Considering both cases, we may realize that we can just modify the range of the summation to j∈max(1,2k−n+1)..k and adopt the case n−r>k in Equation 4 for all terms in the summation. Therefore, we have Pn,k,k=Yk(1−Y)n−k+j=max(1,2k−n+1)∑kYjYk−j(1−Y)Pn−j−(k−j)−1,k−j+1=Yk(1−Y)n−k+Yk(1−Y)k′=1∑min(k,n−k−1)Pn−k−1,k′,
where in the last line we changed the summation index to k′:=k−j+1 to simplify it. Because Pn−k−1,0=Pn−k−1,0,0=(1−Y)n−k−1 according to Equation 3, we can combine the two terms into one summation to get the final result for n>k=r>0: Pn,k,k=Yk(1−Y)k′=0∑min(k,n−k−1)Pn−k−1,k′.(5) Noticing the obvious fact that ∑k=0nPn,k=1, the above equation can be simplified, when
k≥n−k−1, to Pn,k,k=Yk(1−Y).(6) This simplification is not specially useful, but it can be used to simplify the calculation in the program.
Then, for n>k>0, express Pn,k in terms of Pn,k,r by summing over r, and substitute previous results: Pn,k=r=0∑kPn,k,r=Pn,k,0+Pn,k,k+r=1∑k−1Pn,k,r=(1−Y)Pn−1,k+Yk(1−Y)k′=0∑min(k,n−k−1)Pn−k−1,k′=+r=1∑min(k−1,n−k−1)Yr(1−Y)Pn−r−1,k=(1−Y)Ykk′=0∑min(k,n−k−1)Pn−k−1,k′+r=0∑min(k−1,n−k−1)YrPn−r−1,k where in the last term r is summed to min(k−1,n−k−1) instead of k−1 because of the different cases in Equation 4.
Finally, consider the edge cases where n=k≥0 and n≥k=0 (trivial), we have the complete resursive relation for Pn,k: Pn,k=⎩⎨⎧Yn,(1−Y)n,(1−Y)Ykk′=0∑min(k,n−k−1)Pn−k−1,k′+r=0∑min(k−1,n−k−1)YrPn−r−1,k,n=k≥0,n≥k=0,n>k>0.(7)
Then, we can write the program to calculate Pn,k:
1
2
3
4
5
6
7
8
9
10
## Returns an array of size m+1,## with the k-th element being the probability P_{m,k}.defcombom(1..m).each_with_object[[1]]do|n,dp|dp[n]=(1..n-1).each_with_object[(1-Y)**n]do|k,dpn|dpn[k]=(1-Y)*(Y**k*(0..[k,n-k-1].min).sum{dp[n-k-1][_1]}+(0..[k-1,n-k-1].min).sum{Y**_1*dp[n-_1-1][k]})enddp[n][n]=Y**nend.lastend
This algorithm has the same (asymptotic) space and time complexity as the previous one.
Polynomial coefficients
We have wrote programmes to calculate probabilities Pn,k(Y) based on given Y, which we assumed to be a float number. However, float numbers have limited precision, and the calculation may be inaccurate. Actually, the calculation can be done symbolically.
The probability Pn,k is a polynomial of degree (at most) n in Y, and the coefficients of the polynomial are integers. This can be easily proven by using mathematical induction and utilizing Equation 7. Therefore, we can calculate the coefficients of the polynomial Pn,k(Y) instead of calculate the value directly so that we get a symbolic but accurate result.
Both the two DP algorithms above can be modified to calculate the coefficients of the polynomial. Actually, we can define Y to be a polynomial object that can do arithmetic operations with other polynomials or numbers, and then the programmes can run without any modification. Here, I will modify the second DP algorithm to calculate the coefficients of the polynomial.
We can also utilize Equation 6 to simplify the calculation. Considering the edge cases involved in min(k,n−k−1) and min(k−1,n−k−1), there are three cases we need to consider:
Case k>n−k−1: Equation 6 can be applied, and r is summed to n−k−1.
Case k=n−k−1 (can only happen when n is odd): Equation 6 can be applied, and r is summed to k−1.
Case k<n−k−1: Equation 6 cannot be applied, and r is summed to k−1.
Then, use arrays to store the coefficients of the polynomial Pn,k(Y), and we can write the program to calculate the coefficients:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
## Returns a nested array of size m+1 times m+1,## with the j-th element of the k-th element being the coefficient of Y^j in P_{m,k}(Y).defcombo_pcm(1..m).each_with_object[[[1]]]do|n,dp|dp[n]=Array.new(n+1){Array.newn+1,0}# dp[n][0] = (1-Y)**n0.upto(n-1){dp[n][0][_1]=dp[n-1][0][_1]}# will be multiplied by 1-Y later1.upton/2-1do|k|# dp[n][k] = (1-Y) * (Y**k * (0..k).sum { |j| dp[n-k-1][j] } + (0..k-1).sum { |r| Y**r * dp[n-r-1][k] })0.upto(k){|j|0.upto(n-k-1){dp[n][k][_1+k]+=dp[n-k-1][j][_1]}}0.upto(k-1){|r|0.upto(n-r-1){dp[n][k][_1+r]+=dp[n-r-1][k][_1]}}endifn%2==1k=n/2# dp[n][k] = (1-Y) * (Y**k + (0..k-1).sum { |r| Y**r * dp[n-r-1][k] })dp[n][k][k]=10.upto(k-1){|r|0.upto(n-r-1){dp[n][k][_1+r]+=dp[n-r-1][k][_1]}}end((n+1)/2).upton-1do|k|# dp[n][k] = (1-Y) * (Y**k + (0..n-k-1).sum { |r| Y**r * dp[n-r-1][k] })dp[n][k][k]=10.upto(n-k-1){|r|0.upto(n-r-1){dp[n][k][_1+r]+=dp[n-r-1][k][_1]}}end0.upto(n-1){|k|n.downto(1){dp[n][k][_1]-=dp[n][k][_1-1]}}# multiply by 1-Y# dp[n][n] = Y**ndp[n][n][n]=1end.lastend
Here I list first few polynomials Pn,k(Y) calculated by the above program: n=0123⋮k=011−Y1−2Y+Y21−3Y+3Y2−Y31Y2Y−2Y23Y−5Y2+2Y32Y22Y2−2Y33Y3⋯
When evaluating the polynomials for large n, the result is inaccurate for Y that is not close to 0 because of the limited precision of floating numbers. If Y is closer to 1, we can first find the coefficients of Pn,k(1−X) and then substitute X:=1−Y.
Plots of the probability distributions
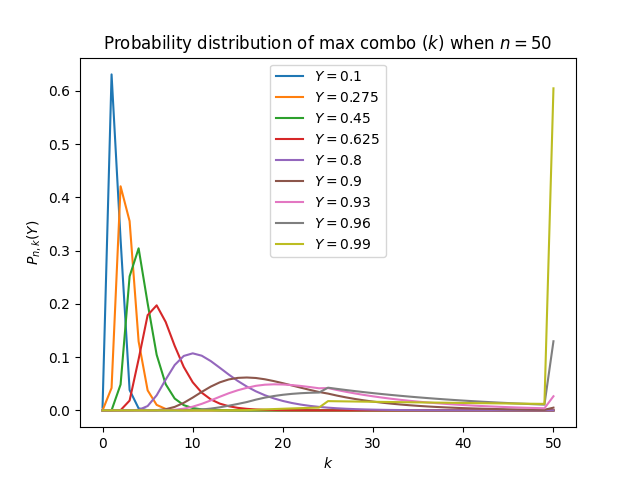
Here are some plots of the probability distribution of max combo k when n=50:
Probability distribution of k when n=50 for different Y
The plots are intuitive as they show that one has higher probability to get a higher max combo when they have a higher success rate.
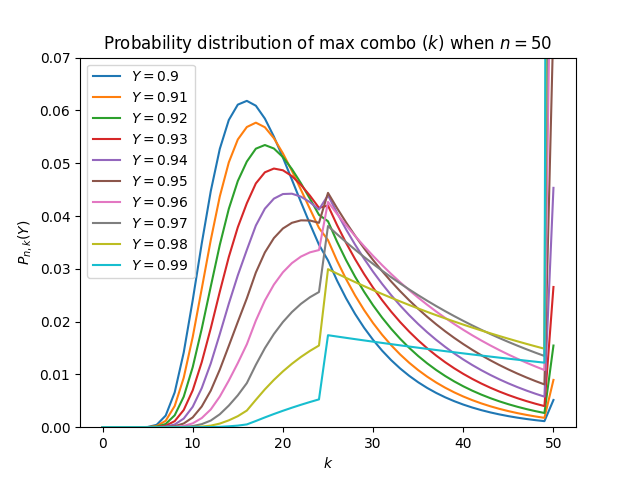
There is a suspicious jump in Pn,k(Y) near k=n/2 when Y is close to 1. We can look at it closer:
Probability distribution of k when n=50 for different Y
In the zoomed-in plot, we can also see a jump in first derivative (w.r.t. k) of Pn,k(Y) near k=n/3. Actually, the jumps can be modeled in later sections when we talk about the case when n→∞.
The case when n→∞
A natural approach is to try substituting Equation 7 into Equation 1 to get a function w.r.t. the unknown function f(y,κ). First, we can easily write the case when y=0 because it means zero success rate, and the only possible max combo is zero: f(y=0,κ)=δ(κ).(8) Similarly, we can easily write the case when y=1: f(y=1,κ)=δ(κ−1).(9)
From now on, we only consider the case when 0<y<1. First, for the case κ=0, according to Equation 7, f(y,κ=0)=n→∞lim(n+1)(1−yn1)n={0,∞,0<y≤1,y=0. The ∞ means that there is a Dirac δ function (shown in Equation 8).
Then, for the case κ=1, according to Equation 7, f(y,κ=1)=n→∞lim(n+1)y=∞. The ∞ means that there is a Dirac δ function. Actually, it is easy to see that there must be a yδ(κ−1) term in the expression of f(y,κ) because the probability of getting a max combo (κ=1) is y.
Define h(y,κ):=f(y,κ)−yδ(κ−1),(10) and then we can get rid of the infinity here.
From now on, we only consider the case when 0<y<1 and 0<κ<1. According to Equation 7,
=f(y∈(0,1),κ∈(0,1))=n→∞lim(n+1)(1−yn1)yκk′=0∑min(κn,n−κn−1)Pn−κn−1,k′(yn1)=n→∞lim(n+1)(1−yn1)+r=0∑min(κn−1,n−κn−1)ynrPn−r−1,κn(yn1)=n→∞limn(1−yn1)⋅n→∞limyκt=0,Δt=n1∑min(κ,1−κ)P(1−κ)n,tn(yn1)+t=0,Δt=n1∑min(κ,1−κ)ytP(1−t)n,κn(yn1)=−lnyn→∞limyκt=0,Δt=n1∑min(κ,1−κ)(1−κ)n1f(y1−κ,1−κt)=−lnyn→∞lim+t=0,Δt=n1∑min(κ,1−κ)yt(1−t)n1f(y1−t,1−tκ)=−lnyn→∞limt=0,Δt=n1∑min(κ,1−κ)(1−κyκf(y1−κ,1−κt)+1−tytf(y1−t,1−tκ))Δt=−lny∫t=0min(κ,1−κ)(1−κyκf(y1−κ,1−κt)+1−tytf(y1−t,1−tκ))dt.
Add back the delta function at κ=1, and we have the integral equation f(y∈(0,1),κ)=−lny∫t=0min(κ,1−κ)(1−κyκf(y1−κ,1−κt)+1−tytf(y1−t,1−tκ))dt+yδ(κ−1).
There are two terms in the integral. Substitute u:=1−κt in the first term, and we have ∫t=0min(κ,1−κ)1−κyκf(y1−κ,1−κt)dt=∫0min(1−κκ,1)yκf(y1−κ,u)du=∫0min(1−κκ,1)(yκh(y1−κ,u)+yδ(u−1))du.
Substitute v:=1−tκ in the second term, and we have ∫t=0min(κ,1−κ)1−tytf(y1−t,1−tκ)dt=∫κmin(1−κκ,1)y1−vκf(yvκ,v)vdv=∫κmin(1−κκ,1)(y1−vκh(yvκ,v)+yδ(v−1))vdv.
Further, let (we only consider y∈(0,1) from now on) g(y,κ):=yh(y,κ),(11) then the integral equation becomes g(y,κ)=−lny(∫0min(1−κκ,1)(g(y1−κ,u)+δ(u−1))du+∫κmin(1−κκ,1)(g(yvκ,v)+δ(v−1))vdv).(12)
There is another integral equation for g. Because ∫01f(y,κ)dκ=1, we have ∫01g(y,κ)dκ=y1−1.(13)
Equation 12 and 13 are the equations that we are going to utilize to get the expression for g(y,κ).
The case κ∈(21,1)
In this case, we have min(1−κκ,1)=1, so the Dirac delta functions in Equation 12 should be considered. In this case, it simplifies to g1(y,κ):=g(y,κ∈(21,1))=−lny(yκ−1+∫κ1g(yvκ,v)vdv+1),(14) where Equation 13 is utilized when finding the first term.
We can try to solve Equation 14 by using Adomian decomposition method (ADM). Suppose g1 can be written in a series g1=g1(0)+g1(1)+⋯, and substitute it into Equation 14, and we have g1(0)(y,κ)+⋯=−lny(yκ−1+1+∫κ1(g(0)(yvκ,v)+⋯)vdv). Assume we may interchange integration and summation (which is OK here because we can verify the solution after we find it using ADM). Then,
=g1(0)(y,κ)+g1(1)(y,κ)+⋯=−lny(yκ−1+1)−lny∫κ1g(0)(yvκ,v)vdv−⋯.
If we let g1(0)(y,κ)g1(i+1)(y,κ):=−lny(yκ−1+1),:=−lny∫κ1g(i)(yvκ,v)vdv,i∈N,(15) then we can equate each term in the two series. If the sum g1=∑i=0∞g1(i) converges, then this is a guess of the solution to Equation 14, which we can verify whether it is correct or not.
Using Equation 15, we can find first few terms in the series by directly integrating. The first few terms are g1(0)(y,κ)g1(1)(y,κ)g1(2)(y,κ)g1(3)(y,κ)⋮=−lny(yκ−1+1),=−lny(yκ−1−1+lnyκ−1),=−lny(yκ−1−1−lnyκ−1+21(lnyκ−1)2),=−lny(yκ−1−1−lnyκ−1−21(lnyκ−1)2+61(lnyκ−1)3),
We may then guess that the terms have general formula g1(i)(y,κ)=−lny(yκ−1+i!1(lnyκ−1)i−j=0∑i−1j!1(lnyκ−1)j). Sum up the terms, and we have
g1(y,κ)=i=0∑∞g1(i)(y,κ)=q→∞limi=0∑q−lny(yκ−1+i!1(lnyκ−1)i−j=0∑i−1j!1(lnyκ−1)j)=−lny(explnyκ−1+q→∞lim((q+1)yκ−1−j=0∑qi=j+1∑qj!1(lnyκ−1)j))=−lny(yκ−1+q→∞lim((q+1)yκ−1−j=0∑qj!q−j(lnyκ−1)j))=−lny(yκ−1+q→∞lim(qyκ−1−qj=0∑qj!1(lnyκ−1)j)=−lnyj∑q+yκ−1+lnyκ−1explnyκ−1)=−lny(2+lnyκ−1)yκ−1.
Therefore, we have the final guess of solution g1(y,κ)=−lny(2+lnyκ−1)yκ−1.(16) We can substitute it into Equation 14 to verify that it is indeed the solution.
The case κ∈(31,21)
In this case, we have min(1−κκ,1)=1−κκ∈(21,1). We can then use the same method as in the previous case to find the solution.
First, by Equation 14, g2(y,κ):=g(y,κ∈(31,21))=−lny(∫01−κκg(y1−κ,u)du+∫κ1−κκg(yvκ,v)vdv)=−lny(∫01g(y1−κ,u)du−∫1−κκ1g1(y1−κ,u)du=−lny+∫κ21g2(yvκ,v)vdv+∫211−κκg1(yvκ,v)vdv).
Substitute Equation 13 and 16 into the above equation, and we have g2(y,κ)=−lny(yκ−1+y−κ(1+lny−κ)−2y2κ−1(1+lny2κ−1)∫κ21=−lny+∫κ21g2(yvκ,v)vdv).(17)
Equation 17 can again be solved by ADM though the calculation is much more complicated than the previous case. We may guess g2=∑i=0∞g2(i) is the solution if the series converges, where g2(0)(y,κ)g1(i+1)(y,κ):=−lny(yκ−1+y−κ(1+lny−κ)−2y2κ−1(1+lny2κ−1)),:=−lny∫κ21g(i)(yvκ,v)vdv,i∈N.
The first few terms go too long to be written here before one may find the pattern, so they are omitted here. If you want to see them, use a mathematical software to help you, and you should be able to find the pattern after calculating first six (or so) terms. After looking at first few terms, the guessed general term is g2(i)=−lny(yκ−1+2y2κ−1(i−1−lny2κ−1)−2j=0∑i−1j!i−j−1(lny2κ−1)j−y−κj=0∑i−1j!1(lny2κ−1)j+i!1y−κ(1+lny−κ)(lny2κ−1)i).
Then we can sum it to get a guess of g2.
After some tedious calculation, we have g2(y,κ)=−lny((2+lnyκ−1)yκ−1−(2+4lny2κ−1+(lny2κ−1)2)y2κ−1).(18) On may verify that this is indeed the solution by substituting it into Equation 17.
The case κ∈(41,31)
By using very similar methods but after very tedious calculation, the solution is g3(y,κ):=g(y,κ∈(41,31))=−lny((2+lnyκ−1)yκ−1−(2+4lny2κ−1+(lny2κ−1)2)y2κ−121=−lny+(3lny3κ−1+3(lny3κ−1)2+21(lny3κ−1)3)y3κ−1).(19)
Other cases
After seeing Equation 16, 18, and 19, one may guess the form of solution for other cases.
Guess the form of solution for κ∈(q+11,q1), where q∈1…∞, is
gq(y,κ):=g(y,κ∈(q1,q+11))=s=1∑qΔgs(y,κ), where
Δgs(y,κ):=(−1)sysκ−1lnyj=0∑sj!As,j(lnysκ−1)j, where As,j are coefficients to be determined.
Now, consider the cases q∈2…∞. Because κ∈(q+11,q1),
min(1−κκ,1)=1−κκ∈(q1,q−11). Therefore,
=∫0min(1−κκ,1)(g(y1−κ,u)+δ(u−1))du=∫01g(y1−κ,u)du−p=1∑q−2∫p+11p1gp(y1−κ,u)du−∫1−κκq−11gq−1(y1−κ,u)du=yκ−1−1−p=1∑q−2∫p+11p1s=1∑pΔgs(y1−κ,u)du−∫1−κκq−11s=1∑q−1Δgs(y1−κ,u)du=yκ−1−1−s=1∑q−1(p=s∑q−2∫p+11p1+∫1−κκq−11)Δgs(y1−κ,u)du=yκ−1−1−s=1∑q−1∫1−κκs1Δgs(y1−κ,u)du,
and =∫κmin(1−κκ,1)(g(yvκ,v)+δ(v−1))vdv=∫κq1gq(yvκ,v)vdv+∫q11−κκgq−1(yvκ,v)vdv=∫κq1s=1∑qΔgs(yvκ,v)vdv+∫q11−κκs=1∑q−1Δgs(yvκ,v)vdv=s=1∑q−1∫κ1−κκΔgs(yvκ,v)vdv+∫κq1Δgq(yvκ,v)vdv.
Substitute into Equation 12, and we have s=1∑qΔgs(y,κ)=−lny(yκ−1−1−s=1∑q−1∫1−κκs1Δgs(y1−κ,u)du+s=1∑q−1∫κ1−κκΔgs(yvκ,v)vdv+∫κq1Δgq(yvκ,v)vdv).(20) To simplify later expressions, define Bs,l:=(−1)lj=l∑s(−1)jAs,j.(21)
Now, calculate the integrals in Equation 20. Before that, first we introduce a handy integral formula: ∫(lnw)jdw=(−1)jj!wl=0∑j(−1)ll!(lnw)l+C. This formula can be proved by mathematical induction and integration by parts.
Then, we have =∫1−κκs1Δgs(y1−κ,u)du=∫1−κκs1(−1)sy(su−1)(1−κ)lny1−κj=0∑sj!As,j(lny(su−1)(1−κ))jdu=s(−1)sj=0∑sj!As,j∫1−κκs1(lny(su−1)(1−κ))jd(y(su−1)(1−κ))=s(−1)sj=0∑sj!As,j∫y(s+1)κ−11(lnw)jdw=s(−1)sj=0∑sj!As,j(−1)jj!(1−y(s+1)κ−1l=0∑j(−1)ll!(lny(s+1)κ−1)l)=s(−1)sj=0∑s(−1)jAs,j−s(−1)sy(s+1)κ−1l=0∑s(−1)ll!(lny(s+1)κ−1)lj=l∑s(−1)jAs,j=(−1)s(sBs,0−s1y(s+1)κ−1l=0∑sl!Bs,l(lny(s+1)κ−1)l).=∫κ1−κκΔgs(yvκ,v)vdv=∫κ1−κκ(−1)syvκ(sv−1)lnyvκj=0∑sj!As,j(lnyvκ(sv−1))jvdv=(−1)sj=0∑sj!As,j∫κ1−κκ(lnyvκ(sv−1))jd(yvκ(sv−1))=(−1)sj=0∑sj!As,j∫ysκ−1y(s+1)κ−1(lnw)jdw=(−1)sj=0∑sj!As,j(−1)jj!(y(s+1)κ−1l=0∑j(−1)ll!(lny(s+1)κ−1)l=(−1)sj=0∑sj!As,j(−1)jj!−ysκ−1l=0∑j(−1)ll!(lnysκ−1)l)=(−1)s(y(s+1)κ−1l=0∑sl!Bs,l(lny(s+1)κ−1)l−ysκ−1l=0∑sl!Bs,l(lnysκ−1)l).=∫κq1Δgq(yvκ,v)vdv=(−1)q(Bq,0−yqκ−1l=0∑ql!Bq,l(lnyqκ−1)l).
Substitute these results into Equation 20, and we have =s=1∑q(−1)sysκ−1lnyj=0∑sj!As,j(lnysκ−1)j=−lny(l∑syκ−1−1=−lny−s=1∑q−1(−1)s(sBs,0−s1y(s+1)κ−1l=0∑sl!Bs,l(lny(s+1)κ−1)l)=−lny+s=1∑q−1(−1)s(y(s+1)κ−1l=0∑sl!Bs,l(lny(s+1)κ−1)l−ysκ−1l=0∑sl!Bs,l(lnysκ−1)l)=−lny+(−1)q(Bq,0−yqκ−1l=0∑ql!Bq,l(lnyqκ−1)l)).
Cancel factor lny on both sides, and we have =s=1∑q(−1)sysκ−1j=0∑sj!As,j(lnysκ−1)j=−yκ−1+1=+s=1∑q−1(−1)ssBs,0−s=2∑qs−1(−1)s−1ysκ−1l=0∑s−1Bs−1,ll!(lnysκ−1)l=−s=2∑q(−1)s−1ysκ−1l=0∑s−1Bs−1,ll!(lnysκ−1)l+s=1∑q−1(−1)sysκ−1l=0∑sBs,ll!(lnysκ−1)l=−(−1)qBq,0+(−1)qyqκ−1l=0∑qBq,ll!(lnyqκ−1)l=1+s=1∑q−1s(−1)sBs,0−(−1)qBq,0=−yκ−1(1+B1,0−B1,1lnyκ−1)=+s=2∑q(−1)sysκ−1(l=0∑s−1(s−1sBs−1,l+Bs,l)l!(lnysκ−1)l+Bs,ss!(lnysκ−1)s)(∗)(∗∗)(∗∗∗)
Equate the coefficients in Line (*) with the corresponding ones on the LHS, and we have 0=1+s=1∑q−1s(−1)sBs,0−(−1)qBq,0. This equation holds for any q∈2…∞, so {(−1)qBq,0=1+∑s=1q−1s(−1)sBs,0,(−1)q+1Bq+1,0=1+∑s=1qs(−1)sBs,0,q∈2…∞.
Subtract the two equations, and we have Bq+1,0=−qq+1Bq,0,q∈2…∞.(22) Equation 22 can determine Bq,0 for all q∈2…∞ once B2,0 is determined. The relationship between B1,0 and
B2,0 cannot be described by Equation 22, but is given by B2,0=1−B1,0.(23)
Equate the coefficients in Line (**) with the corresponding ones on the LHS, and we have A1,0=1+B1,0,A1,1=B1,1. By Equation 21, this is equivalent to
A1,0=1+A1,0−A1,1,A1,1=A1,1. Therefore, A1,1=1, and thus B1,1=1.(24)
Equate the coefficients in Line (***) with the corresponding ones on the LHS, and we have As,l=s−1sBs−1,l+Bs,l,As,s=Bs,s. By Equation 21,
Bs,l=As,l−Bs,l+1 for l∈0…s, and As,s=Bs,s is always true. Therefore,
0=s−1sBs−1,l−Bs,l+1. This equation is true for any s∈2..q and l∈0…s. Because q is arbitrary, we can change the variable s to q and the equation tells us exactly the same information. Therefore, Bq,l=q−1qBq−1,l−1,q∈2…∞,l∈1..q.(25)
Equation 22, 23, 24, and 25 are sufficient to determine Bq,l for all q∈1…∞ and l∈0..q up to one arbitrary parameter. Define the arbitrary parameter b:=1−B1,0, then the first few Bq,l are q=1234⋮l=01−b2b−3b4b⋱112−2b3b−4b223−3b4b334−4b44 The general formula for Bq,l is
Bq,l=⎩⎨⎧q,q(1−b),(−1)q+lqb,l=q,l=q−1,l∈0..q−2, which may be proved by mathematical induction.
Actually, one may find b=0 by simply comparing with the results in Equation 16, 18, or 19. Another way to find b is comparing with Eqution 13. Here I wil show the latter approach.
=∫01g(y,κ)dκ=q=1∑∞∫q+11q1gq(y,κ)dκ=q=1∑∞∫q+11q1s=1∑qΔgs(y,κ)dκ=s=1∑∞q=s∑∞∫q+11q1Δgs(y,κ)dκ=s=1∑∞∫0s1Δgs(y,κ)dκ=s=1∑∞∫0s1(−1)sysκ−1lnyj=0∑sj!As,j(lnysκ−1)jdκ=s=1∑∞s(−1)sj=0∑sj!As,j∫0s1(lnysκ−1)jd(ysκ−1)=s=1∑∞s(−1)s(Bs,0−y−1l=0∑sBs,ll!(lny)l)=−(1−b)+y−1((1−b)−lny)=+s=2∑∞s(−1)s((−1)ssb−y−1(l=0∑s−2(−1)s+lsbl!(lny)l=+s=2∑∞s(−1)s(s∑∞(−1)ssb−y−1+s(1−b)(s−1)!(−lny)s−1+ss!(−lny)s))=b−1+y−1(1−b−lny)+y−1s=2∑∞((s−1)!(lny)s−1−s!(lny)s)=+bs=2∑∞(1−y−1l=0∑s−1l!(lny)l)=b−1+y−1(1−b−lny)+y−1((explny−1)−(explny−lny−1))=+bq→∞lims=2∑q(1−y−1l=0∑s−1(lny)l)=b−1+y−1(1−b)+bq→∞lim(q−1−y−1(q−1+l=1∑q−1l!q−l(lny)l))=b−1+y−1(1−b)+b(−1+y−1+lny)=y−1−1+blny.
Compare the result with Equation 13, we have b=0.
The table of Bq,l is now q=1234⋮k=01000⋱11200223033444 The table of As,j is then
s=1234⋮j=02200⋱11430226433844 The general formula for As,j is As,j=⎩⎨⎧s,2s,0,j∈{s,s−2},j=s−1,j∈0..s−3.(26)
Therefore, the functions Δgs are Δgs(y,κ)=⎩⎨⎧−yκ−1lny(2+lnyκ−1),(s−2)!s(−1)sysκ−1lny(lnysκ−1)s−2(1(lnysκ−1)2+s−12lnysκ−1+s(s−1)1(lnysκ−1)2),s=1s∈2…∞.
Therefore, the functions gq are gq(y,κ)=−yκ−1lny(2+lnyκ−1)+lnys=2∑q(s−2)!s(−1)sysκ−1(lnysκ−1)s−2(1s!(−1)sgq(y,κ)=+s−12lnysκ−1+s(s−1)1(lnysκ−1)2)(27) (the formula is also applicable to q=1).
Edge cases
Now we have covered almost all cases. The only cases that we have not covered are the cases when κ=q1, where q∈2…∞. The discontinuity in g at κ=q1 is =g(y,q1+)−g(y,q1−)=−Δgq(y,q1)={−2lny,0,q=2,q∈3…∞.(28) Therefore, for q∈3…∞, the function g has defined limit at κ=q1, and the value of g here should just be the limit value. Now, the only problem is at κ=21. We should determine whether the value of g at κ=21 is its left limit or right limit.
Looking at Equation 12, one may see that the discontinuity at κ=21 is due to the Dirac δ function in the integrand. Therefore, whether g at κ=21 is g1 or g2 depends on whether the Dirac δ function is within the integrated interval. If it is, then g at κ=21 is g1; otherwise, it is
g2.
The inclusion of the Dirac δ function in the integrated interval corresponds to the inclusion of the highest term in the summation in Equation 7. Because both min(k,n−k−1) and min(k−1,n−k−1) equal n−k−1 when n=2k, the highest term in the summation can be reached, so the Dirac δ function is within the integrated interval. Therefore, g at κ=21 is g1.
Therefore, we may conclude that for any κ∈(0,1), g(y,κ)=g⌈κ1⌉−1(y,κ).(29)
Another edge case that is interesting to consider is when κ→0+. However, because the domain of g does not include κ=0 by definition, so we do not need to consider this case. By some mathematical analysis techniques, one may prove that the limit of g as κ→0+ is 0.
The solution
Substitute Equation 27 into Equation 29, and we have g(y,κ)=−yκ−1lny(2+lnyκ−1)+lnys=2∑⌈κ1⌉−1(s−2)!s(−1)sysκ−1(lnysκ−1)s−2(1s!(−1)sg(y,κ)=+s−12lnysκ−1+s(s−1)1(lnysκ−1)2)
Substitute the result into Equation 11 and then Equation 10, and also consider Equation 8 and 9, and we have f(y,κ)=⎩⎨⎧δ(κ),0,yδ(κ−1)−yκlny(2+lnyκ−1)+lny∑s=2⌈κ1⌉−1(s−2)!s(−1)sysκ(lnysκ−1)s−2(1(lnysκ−1)2+s−12lnysκ−1+s(s−1)1(lnysκ−1)2),y=0,κ∈[0,1],y∈(0,1],κ=0,y∈(0,1],κ∈(0,1].(30)
Plots of the probability density functions
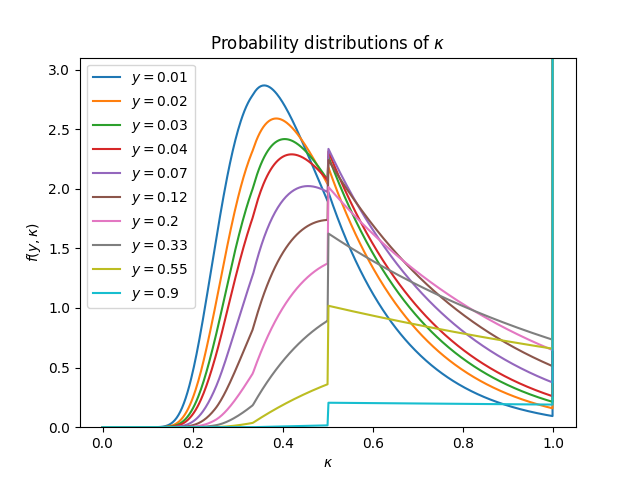
Here are plots of the function f(y,κ) whose expression is given by Equation 30:
Probability distribution of κ when n→∞
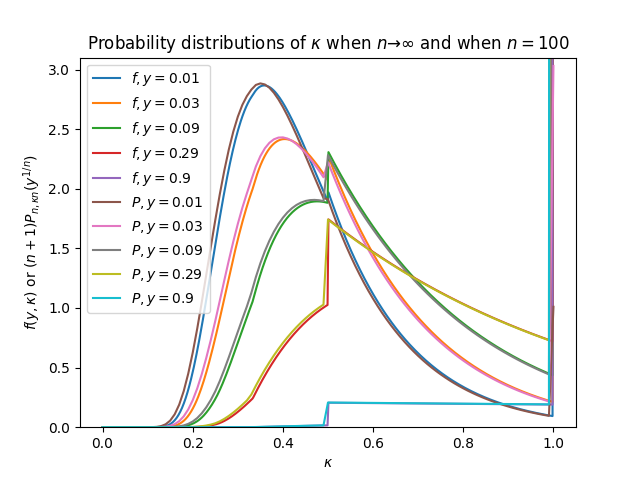
We can compare it with a plot of the distributions when n is finite (say, 100), and we may see that they are very close:
Probability distribution of κ when n→∞ and when n=100 compared
We have not investigated the asymptotic behavior of the error if we approximate the distribution with finite n by the distribution with infinite n, but we may expect that the error is small enough for applicational uses when n is a usual note count in a rhythm game chart (usually at least 500).
Moments
It may be interesting to calculate the moments of the distribution.
We need to evaluate μν(y):=∫01κνf(y,κ)dκ. First, calculate =∫0s1κν(lnysκ−1)jysκ−1lnydκ=∫y−11(slogyw+1)ν(lnw)jdw=sν+11p=0∑ν(pν)(lny)p1∫y−11(lnw)j+pdw=sν+11p=0∑ν(pν)(lny)p(−1)j+p(j+p)!(1−y−1l=0∑j+pl!(lny)l).=∫0s1κνΔgs(y,κ)dκ=j=0∑s(−1)sj!As,jsν+11p=0∑ν(pν)(lny)p(−1)j+p(j+p)!(1−y−1l=0∑j+pl!(lny)l)=sν+1(−1)sp=0∑ν(pν)(lny)p(−1)p(j=0∑sj!(j+p)!(−1)jAs,j−y−1j=0∑sj!(j+p)!(−1)jAs,jl=0∑j+pl!(lny)l).
Now, the only problem is how to get Dν,p,l. Substitute Equation 26 into Equation 31, and after some calculations, we can get the general formula of Bs,l,p: Bs,l,p=(s−1)!(−1)smax(l,s+p−2)!⋅⎩⎨⎧p(p−1),p−s,1,l∈0..s+p−2,l=s+p−1,l=s+p. Substitute it into Equation 32, and notice the edge cases, we can get
Dν,p,l=⎩⎨⎧p(p−1)∑s=1∞sν+1(s−1)!(s+p−2)!,p!(p−1)+p(p−1)∑s=2∞sν+1(s−1)!(s+p−2)!,(l−p)ν+1(l−p−1)!l!−(l−p+1)ν+1(l−p)!l!(2p−l−1)+p(p−1)∑s=l−p+2∞sν+1(s−1)!(s+p−2)!,l∈0..p−1,l=p,l∈p+1…∞=⎩⎨⎧p(p−1)((p−1)!+Sν,p),(l−p)ν+1(l−p−1)!l!−(l−p+1)ν+1(l−p)!l!(2p−l−1)+p(p−1)(Sν,p−∑s=2l−p+2sν+1(s−1)!(s+p−2)!),l∈0..p,l∈p+1…∞,
where the infinite sum Sν,p:=s=2∑∞sν+1(s−1)!(s+p−2)!. There is no closed form for Sν,p, but we may express it in terms of Stirling numbers of the first kind and the Riemann ζ function. For p∈1..ν, we have
Sν,p=−(p−1)!+s=1∑∞sν+1s(s+1)⋯(s+p−2)=−(p−1)!+s=1∑∞sν+11λ=0∑p−1[p−1λ]sλ=−(p−1)!+λ=0∑p−1[p−1λ]ζ(ν−λ+1),
where [⋅⋅] denotes (unsigned) Stirling numbers of the first kind. For p=0, we have Sν,0=s=2∑∞sν+1(s−1)1=s=2∑∞sν+1(s−1)1−s=2∑∞s(s−1)1+1=1−s=2∑∞sν+11s−1sν−1=ν+1−s=1∑∞sν+11λ=0∑ν−1sλ=ν+1−λ=0∑ν−1ζ(ν−λ+1).
Then, the following steps will be extremely tedious, and I doubt there will be a closed form for our final result, so I will not continue to find the general formula for the moments.
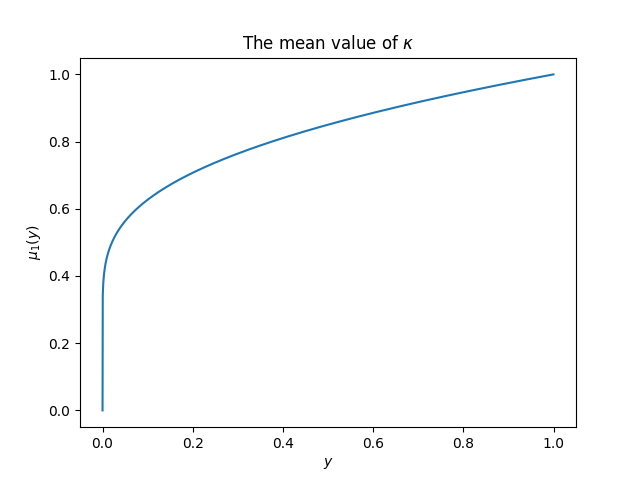
However, we may obtain the first moment (mean) analytically. We have D1,0,l={−1,l1−l+11,l=0,l∈1…∞,D1,1,l={0,l1+l−11,l=0,1,l∈2…∞.μ1(y):=∫01κf(y,κ)dκ=y+y∫01κg(y,κ)dκ=lnyliy−ln(−lny)−γ, where li is the logarithmic integral function, and γ is the Euler–Mascheroni constant. The function seems undefined when
y=0 or y=1, but it has limits at these points: μ1(y→0+)=0,μ1(y→1−)=1, which is intuitive. (This function tends to 0 very slowly when y→0+, so slowly that I almost did not believe that when I did the numerical calculation first.)
The plot:
The mean value of κ vs. y
We should also be able to find other statistical quantities like the median, the mode, the variance, etc., but they seem do not have closed forms.
Some interesting observations
The probability distribution of κ seems to tend to be a uniform distribution plus a Dirac δ distribution when y is very close to 1. This phenomenon is very visible if we look at the plot of f(y=0.9,κ).
In other words, the distribution seems like f(y≈1,κ)≈(1−y)U(21,1)+yδ(κ−1), where U(a,b) denotes the uniform distribution on the interval [a,b].
This can be justified by expanding f(y,κ) in Taylor series of 1−y and retaining the first-order terms only. Note that ya(lny)b=(y−1)b(1+(2b−a)(1−y)+⋯), so the only case where the Taylor series has a non-zero first-order term is when b=1 or b=0. In Equation 30, we can see that the power on lny is at least one for each term (because of the general lny factor in front), so only the terms with no lny factors but the general one will have a first-order term. In this case, the first order term is proportional to y−1, and the proportional coefficient is just the coefficient in the front of the term in f, which is independent of κ because
κ only appears in the power index of y.
Therefore, we may see that only q=1 and q=2 terms have a non-zero first-order term, and they are respectivey −2(y−1) and 2(y−1). This means that when y is very close to 1, f(y≈1,κ)≈{2(1−y),0,κ∈(21,1),κ∈(0,21). This is exactly the uniform distribution.
There is an intuitive way to explain the appearance of the uniform distribution. When y is very close to 1, the probability of getting one combo break (1−Y) is already very small, so it is very unlikely that there are two or more combo breaks. Assuming there is only one combo break and it may appear anywhere with equal probability. The combo break will cut the string of notes into two pieces, and the length of the larger piece is the max combo, which is uniformly distributed between half note count and full note count.
Every rhythm game player knows: never celebrate too early. You never know whether you will miss near the end. It is then interesting to know what is the probability of getting almost a full combo, i.e. what is the probability of getting κ very close to 1.
If we find the limit of f(y,κ) as κ→1−, it is f(y,κ→1−)=−2ylny. There is a peak of this probability density at y=e−1. Therefore, when y=e−1, the probability of getting κ very close to 1 is the largest.
When does y=e−1, then? Because y=Yn=(1−nnb)n, where nb is the average number of combo breaks, then it tends to e−nb when n→∞. Therefore, the probability of getting almost a full combo is the highest when your average number of combo breaks is exactly one.
From the plot, it seems that the probability of getting κ a little bit higher than 21 is always higher than the probability of getting κ a little bit lower than 21. According to Equation 28, the jump in f(y,κ) at κ=21 is
f(y,κ→21+)−f(y,κ→21−)=−2ylny. Interestingly, this coincides with f(y,κ→1−).
Define y0(κ):=argmaxy∈[0,1]f(y,κ), and then it seems that y0:[0,1]→[0,1] is injective but not surjective. It is strictly increasing, and there is a jump at κ=21 and at κ=1.
It has an elementary expression on [21,1): y0(κ∈[21,1))=expκ(κ−1)−2κ+1+2κ2−2κ+1.
Some applications
In Phigros, one should combo at least 60% of the notes to get a white V () rank. If on average I have one combo break in a chart, which has 1300 notes, what is the probability of comboing at least 60% of the notes in the chart?
Solution. The success rate is Y=13001300−1,y=Y1300≈e−1. The probability of comboing more than 60 of the notes is =∫60%1f(y,κ)dκ=y+∫0.61−yκlny(2+lnyκ−1)dκ≈e−1+∫0.61e−κ(3−κ)dκ=57e−53≈0.768.
Oh, my god! It is hard to come up with application problems. I hope readers find out the applications themselves.
 (prompts)
(prompts)