Jekyll2024-10-21T19:17:19-07:00https://ulysseszh.github.io/feed.xmlUlysses’ tripHere we are at the awesome (awful) blog written by UlyssesZhan!UlyssesZhanulysseszhan@gmail.comSome understanding of Grassmann numbers out of intuition2024-10-10T22:40:02-07:002024-10-10T22:40:02-07:00https://ulysseszh.github.io/math/2024/10/10/grassmann-numThis article (except the introduction and the afterwords) is my answer to one of the homework problems that I did when I took a quantum field theory course. The original problem asked to verify the formula for linear change of variables in integration. It was originally written on 2024-02-06.
Introduction
Although Grassmann numbers are purely mathematical concept, but like most people, I was introduced to them in physics class. I then had the natural question: how to formally define Grassmann numbers? In a homework given by my professor of QFT course, I found that I had to answer the question to do a problem in the homework in a way that I am satisfied with.
Numbers
Let (G0,+) and (G1,+) be two abelian groups such that G0∩G1={0}. For convenience, for any k∈N, define Gk:=Gkmod2. Define a multiplication on
G0∪G1 such that
multiplication is associative, non-degenerate, and distributive over addition;
G0 are commuting numbers and G1 are anticommuting numbers: ∀ψ1∈Gk1,ψ2∈Gk2:ψ1ψ2=(−)k1k2ψ2ψ1;
and there is a unity 1∈G0 such that 1+⋯+1=0 for any finite number of summands.
We then have to have ∀ψ1∈Gk1,ψ2∈Gk2:ψ1ψ2∈Gk1+k2. Therefore, G0 is a commutative ring with characteristic zero, and G1 is a
G0-module. We can then define linear functions with this structure. In this sense, the multiplication on G1 defines a symplectic bilinear form.
These are not enough to define every property we need for G0 and G1. I will introduce more properties as axioms later.
Tensors
It seems that we need this property as an axiom: for any linear function λ:Gk→G0, ∃!φ∈Gk:λ=(ψ↦φψ). I call this property the first representation property, analog to the Riez representation theorem. I will call linear functions that maps objects to G0linear functionals, and the dual space of a G0-module as the set of all linear functionals on it.
With the fist representation property, we can identify Gk with its dual space so that any multilinear map (tensor) have well-defined components. For any k-linear map T:(G1n)k→G0 (or alternatively called a rank-k tensor on G1n), we can write it uniquely in the form
T(ψ1,…,ψk)=ψ1i1⋯ψkikai1⋯ik, where the components
Ti1⋯ik∈Gk, and the dummy indices are summed from 1 to n. Denote the set of all rank-k tensors on G1n as T1nk.
Similarly, we can define k-linear maps T:(G0n)k→G0 (or rank-k tensors on G0n), whose components are in G0, and denote the set of all of them as T0nk. Tensors from T0nk and those from
T1nk can be multiplied and contracted together without any problems. However, the result of these operations may not be in T0nk or T1nk, but some tensor that takes arguments from both G0n and G1n.
Linear endomorphisms
Here we will need another property as an axiom: for any linear function λ:Gk→Gk, ∃!φ∈G0:λ=(ψ↦φψ). I call this property the second representation property. This is very similar to the first representation property, but it covers linear endomorphisms on Gk instead of linear functionals on Gk.
With the second representation property, we can prove that any possible linear endomorphism J on Gkn can be written as a unique matrix in G0n×n acting on the components of the argument: J(ψ)i=Jijψj, where Jij∈G0 are called the components of the linear endomorphism J. From now on, we do not need to distinguish between matrices in
G0n×n and linear endomorphisms on Gkn.
For a matrix J∈G0n×n, we can define its determinant as detJ:=J1i1⋯Jninεi1⋯in[n]∈G0, where
ε[n]∈T0nn is the Levi-Civita symbol, which is a completely antisymmetric tensor on G0n whose components take values in {−1,0,1}⊂G0.
Analytic functions
For any T∈T1nk, define a degree-kmonomial on G1n as MT:G1n→G0,ψ⟼T(ψ,…,ψ), which is a degree-k homogeneous function on G1n. Note that different tensors may correspond to the same monomial. Especially, for any
k>n, a degree-k monomial must be trivial (send any input to zero). Also, if there is any pair of indices such that T is symmetric in exchanging them, then the monomial MT must be trivial. Therefore, we only need to consider the those completely antisymmetric tensors when studying monomials. Denote the set of all completely antisymmetric rank-k tensors on G1n as T1n[k], and then the fact that we only need antisymmetric tensors to define monomials can be written as
MT1n[k]=MT1nk.
An analytic functionf on G1n is defined as a sum of monomials: f:G1n→G0,ψ⟼k∑MT[k](ψ), where
T[k]∈T1n[k], whose components may be referred to as expansion coefficients. We do not need to worry about the convergence because this is a finite sum (k≤n). Denote the set of all analytic functions on G1n as An.
Two properties of analytic functions:
If f∈An, then for any δ∈G1n, the translation (ψ↦f(ψ+δ))∈An.
If f∈An, then for any J∈G0n×n, the linear transformation in the argument f∘J∈An.
Integrals
Now we define that a linear function ∫:An→Gn is called an integral if it satisfies the following property: ∀f∈An,δ∈G1n:∫f=∫ψ↦f(ψ+δ), which intuitively means that an integral is invariant under translation.
With this definition of an integral, we are now interested in the most general form of an integral.
Because ∫ is linear, we can find its form on monomials, and then sum them up to get the form on all analytic functions. As a linear function on monomials, it must be of the form (by the second representation property) ∫MT[k]=ci1⋯ik[k]Ti1⋯ik[k], where
c[k]∈T0n[k] does not depend on T[k]. Plug this form into the translational invariance of ∫, and we have ci1⋯ik[k]Ti1⋯ik[k]=∫ψ↦(ψi1+δi1)⋯(ψik+δik)Ti1⋯ik[k]=∫ψ↦l∑(lk)ψi1⋯ψilδil+1⋯δikTi1⋯ik[k]=l∑(lk)ci1⋯il[l]δil+1⋯δikTi1⋯ik[k]
(here the binomial coefficient should be regarded as its image under the natural ring homomorphism from Z to G0, which must be non-zero because G0 has characteristic zero). Regarding T[k] as the independent variable, this equation is a homogeneous linear equation L[k](T[k])=0 associated with the linear operator L on T1n[k] defined as Li1⋯ik[k]:=ci1⋯ik[k]−l∑(lk)ci1⋯il[l]δil+1⋯δik.
For the solution set of the linear equation to be the whole space T1n[k], we need L[k]=0. Again by the second representation property, we need all the components to vanish (strictly speaking, we need the completely antisymmetric part to vanish, but they are already completely antisymmetric): ∀k≤n,δ∈G1n,i1,…,ik:ci1⋯ik[k]−l∑(lk)ci1⋯il[l]δil+1⋯δik=0.
The first term cancels with the l=k term in the sum, so this equation does not impose any requirement for c[k] but only impose requirements for c[l] with l<k. Then, we can induce on k: the equation for k=0 does nothing; the equation for k=1 requires c[0] to vanish; the equation for k=2, given that c[0] vanishes, now requires c[1] to vanish; and so on. For each
k, the equation additionally requires c[k−1] to vanish. Finally, when we reach k=n, which is the end of the induction, we require c[l] to vanish for all l<n, and there is no requirement for c[n]. Therefore, the integral of any monomial is zero except for the degree-n monomial, and thus we only need to consider the nth degree term when finding the integral of an analytic function.
Note that Tkn[n]=Gkε[n] (in other words, the most general form of a completely antisymmetric rank-n tensor on Gkn is a constant in Gk times the Levi-Civita symbol). Therefore, ci1⋯in[n]=cnεi1⋯in[n],Ti1⋯in[n]=dεi1⋯in[n],
where cn=∈G0 and d∈Gn. The definition of an integral does not impose any requirement for cn, so it can be any element in G0. For convenience, define cn:=1 for all n, and then we have ∫Mdε[n]=εi1⋯in[n]dεi1⋯in[n]=n!d, where n! is the image of n! under the natural ring homomorphism from Z to G0. The integral of any monomial with its degree different from n is zero, so the integral of any analytic function is just that of its degree-n term:
∫ψ↦k∑MT[k](ψ)=n!T1⋯n[n].
Linear change of integrated variable
Now, for a linear endomorphism J∈G0n×n and an analytic function f∈An, consider the integral ∫f∘J. We only needs to consider the degree-n monomial term, which is
MT[n](J(ψ))=Ji1j1ψj1⋯Jinjnψjndεi1⋯in[n],
where T[n]=dε[n] is used. Notice that εi1⋯inJi1j1⋯Jinjn itself is a rank-n completely antisymmetric tensor on G0n, so it can also be written as a constant times
ε[n]. By letting j1,…,jn be 1,…,n respectively, we see that the constant is just detJ. Therefore, MT[n](J(ψ))=MT[n](ψ)detJ. By the linearty of the integral, we have
∀f∈An:∫f∘J=detJ∫f.
Afterwords
Actually, before I wrote my answer, I already know the exterior algebra. In this article, my definition to Grassmann numbers is more abstract and puts the commuting numbers and anticomuuting numbers in more equal footings. This definition is closer to what I intuitively think Grassmann numbers could be.
There are several potential problems in this article:
Some axioms are given, but I did not prove that they are consistent.
Some claims are made without proof. They may turn out to be wrong.
I did not prove that the usual definition of Grassmann numbers (with exterior algebra) can be formulated as a special case of my definition.
I am not educated in supersymmetry, which is where Grassmann numbers are applied most. I only made my definition comply with the properties of Grassmann numbers that I have learned for doing the path integral of fermionic fields.
]]>UlyssesZhanulysseszhan@gmail.comThe notational convenience of imaginary time in the derivation of the metric in Poincaré coordinates2024-09-10T14:19:33-07:002024-09-10T14:19:33-07:00https://ulysseszh.github.io/physics/2024/09/10/poincare-coord-imagIntroduction
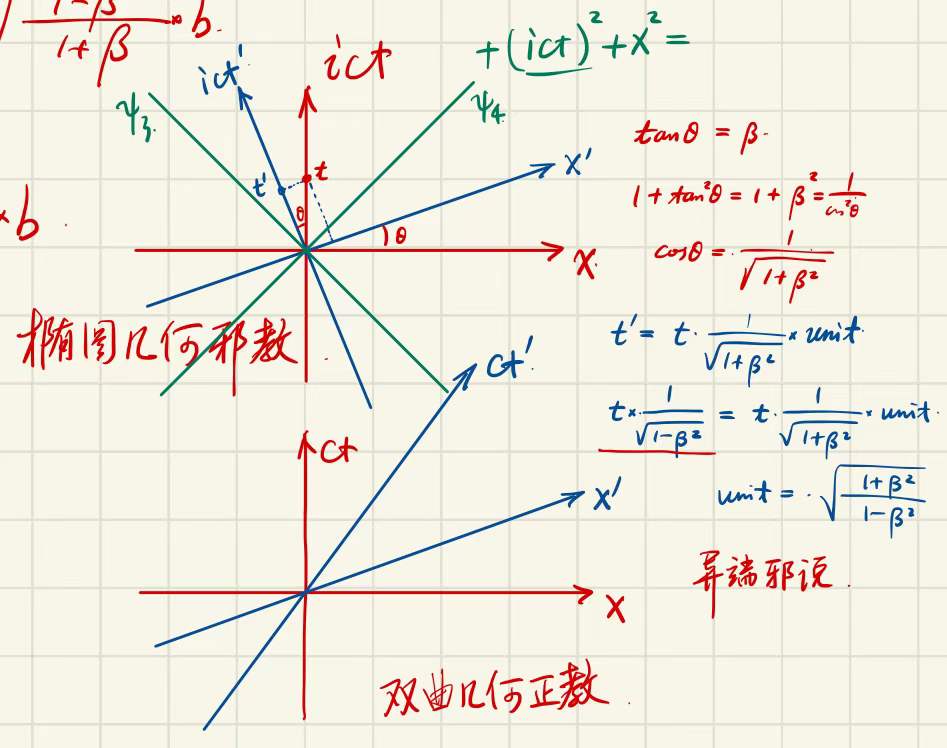
There are two major conventions for the metric signature: (+,−,−,−) (west coast) and (−,+,+,+) (east coast). However, the first convention that I have met in my journey of learning physics is neither of them: the imaginary time. Shortly after, I started using the west coast convention, so I never really used the imaginary time convention seriously. I personally dislike the imaginary time convention, and so do most people in the physics community and history, which is why most modern textbooks use either the west coast or the east coast convention. One of my past physics teachers deemed the imaginary time convention to be a heresy (异端邪说).
The teacher’s writing
However, in some cases, the imaginary time convention can be convenient due to the use of multi-index notation (which is more concise and feature-rich than the Einstein notation). Here is one of such cases: the derivation of the metric in Poincaré coordinates for the anti-de Sitter space.
The d-dimensional anti-de Sitter space AdSd of scale l is defined as the hyperboloid −l2=−T12−T22+i=1∑d−1(Xi)2 in Md−1,2 (the analogue of the Minkowski space, but with signature d−1,2). The Poincaré coordinates are defined as
ztxi:=T1+Xd−1l2,:=T1+Xd−1lT2,:=T1+Xd−1lXi,i=1,…,d−2.
The derivation
Define T:=T1 and X:=Xd−1 just for fun. Then, define two (d−1)-dimensional multi-indices
Y:=(iT2,X1,…,Xd−2),y:=(it,x1,…,xd−2).
The hyperboloid constraint and the metric (east coast convention) are then X2−T2+Y2=−l2,ds2=dX2−dT2+dY2, which are equivalently (X+T)(X−T)=−l2−Y2,ds2=(dX+dT)(dX−dT)+dY2.(1) The definition of the Poincaré coordinates can be written as
z=X+Tl2,y=lzY, or equivalently X+T=zl2,Y=zly.(2)
Substitute Equation 2 into the first equation in Equation 1. Then, we have X−T=−z−zy2.(3) Differentiate Equation 2 and 3, and we have dX+dT=−z2l2dz,dX−dT=−dz+z2y2dz−z2ydy,dY=l(zdy−z2ydz).
Substitute this into the second equation in Equation 1, and we have ds2=−z2l2dz(−dz+z2y2dz−z2ydy)+l2(zdy−z2ydz)2=z2l2(dy2+dz2).
Finally, substitute back the definition of y, and we have the result ds2=z2l2(−dt2+i=1∑d−2(dxi)2+dz2).
]]>UlyssesZhanulysseszhan@gmail.comThe smallest wave packet in the lowest Landau level2024-07-01T01:01:46-07:002024-07-01T01:01:46-07:00https://ulysseszh.github.io/physics/2024/07/01/landau-wave-packetIntroduction
Exercise 12.5 from Modern Condensed Matter Physics (Girvin and Yang, 2019) asks to construct a Gaussian wave packet in the lowest Landau level in the Landau gauge, such that it is localized as closely as possible around some point R:=(Rx,Ry).
Actually, we can prove that the smallest wave packet is a Gaussian wave packet. Here is the derivation.
The problem
First, for readers who are not familiar with the Landau levels, here is a brief introduction. For an electron confined in the xy plane under a magnetic field B=Bz^, its Hamiltonian is H=2me1(px2+(py−ceBx)2) under the Landau gauge A=Bxy^. Its eigenstates in the position representation are
ψnk(x,y)=eikyHn(lx−kl)e−(x−kl2)2/2l2 labeled by n∈N and k∈R, where Hn is the Hermite polynomial of degree n and
l:=ℏc/eB. States with the same n are degenerate in energy (En=(n+1/2)ℏeB/mec) and make up the nth Landau level. The Landau level with n=0 is called the lowest Landau level.
The problem, now, is this optimization problem: akminst⟨Ψx2+y2Ψ⟩⟨Ψ∣Ψ⟩=1,⟨Ψ∣x∣Ψ⟩=Rx,⟨Ψ∣y∣Ψ⟩=Ry (optimizing ⟨x2+y2⟩ is equivalent to optimizing σx2+σy2 because ⟨x⟩ and ⟨y⟩ are both fixed), where ∣Ψ⟩ is defined as the state whose position representation is
Ψ(x,y)=∫dkakeikye−(x−kl2)2/2l2.
The solution
Consider the moment-generating functionM(u,v):=⟨Ψeux+vyΨ⟩=∬dxdyeux+vy∫dkak∗e−ikye−2l21(x−kl2)2∫dk′ak′eik′ye−2l21(x−k′l2)2=∬dkdk′ak∗ak′∫dxeux−2l21(x−kl2)2−2l21(x−k′l2)22πδ(k′−k−iv)∫dyexp(vy+i(k′−k)y)=2π∫dkak∗ak+ivlπexp(41l2(4ku+u2+2iuv+v2))∫dxexp(ux−2l21(x−kl2)2−2l21(x−(k+iv)l2)2)=2π3/2lexp(41l2(u2+2iuv+v2))∫dkak∗ak+ivekl2u=2π3/2l∫dkak∗(ak+kl2aku+iak′v+41l2(1+2k2l2)aku2+41(l2ak−2ak′′)v2+2il2(ak+2kak′)uv+⋯),
where ak′:=dak/dk and ak′′:=d2ak/dk2. On the other hand, we have M(u,v)=⟨Ψ1+ux+uy+21u2x2+21v2y2+uvxy+⋯Ψ⟩. Compare the expansion coefficients, and we have ⟨Ψ∣Ψ⟩⟨Ψ∣x∣Ψ⟩⟨Ψ∣y∣Ψ⟩⟨Ψx2Ψ⟩⟨Ψy2Ψ⟩=2π3/2l∫dkak∗ak,=2π3/2l3∫dkak∗kak,=2iπ3/2l∫dkak∗ak′,=21π3/2l3∫dkak∗(1+2k2l2)ak,=21π3/2l∫dkak∗(l2−2ak′′)ak.
Define φ(k):=ak2π3/2l. Define fictitious position and momentum operators acting on φ as Ξφ:k↦kφ(k),Πφ:k↦−iφ′(k). Using the constraints of the original optimization problem and abusing the bra–ket notation on φ, we have ⟨φ∣φ⟩=1,⟨φ∣Ξ∣φ⟩=l2Rx,⟨φ∣Π∣φ⟩=−Ry. The objective function then becomes ⟨Ψx2+y2Ψ⟩=21l2+⟨φ∣H∣φ⟩, where H:=Π2/2+l4Ξ2/2 is a fictitious Hamiltonian, which is the Hamiltonian of a harmonic oscillator with mass 1 and angular frequency ω:=l2.
The optimization problem can now be re-stated in terms of ∣φ⟩ as ∣φ⟩minst⟨φ∣H∣φ⟩⟨φ∣φ⟩=1,⟨φ∣Ξ∣φ⟩=Rx/ω,⟨φ∣Π∣φ⟩=−Ry. Physically, this means that we want to find the state of a harmonic oscillator with the given expectation values of position and momentum and the lowest energy. To find it, we can use Hisenberg’s uncertainty principle: ⟨H⟩=21⟨Π2⟩+21ω2⟨Ξ2⟩=21(⟨Π⟩2+σΠ2)+21ω2(⟨Ξ2⟩+σΞ2)=21σΠ2+21ω2σΞ2+21Ry2+21Rx2≥ωσΠσΞ+21R2≥21ω+21R2.
The equality in the first “≥” is achieved when σΠ=ωσΞ, and that in the second “≥” is achieved when the uncertainty principle is saturated. As we know from quantum mechanics, the coherent state of a harmonic oscillator satisfies both conditions. The wavefunction of this state is φ(k)=(πω)1/4exp(−21ω(k−ωRx)2−iRyk). Express the final result in terms of ak:
ak=2π1e−ikRye−2l21(Rx−kl2)2. We may work out the integral to get the wave function of the wave packet: Ψ(x,y)=2πl1exp(−4l21((x−Rx)2+(y−Ry)2−2i(x+Rx)(y−Ry))). This is a Gaussian wave packet centered at R with covariance matrix
Diag(l2,l2).
Further problems
The optimal wave packet is indeed Gaussian. This makes me curious about whether this is a coincidence or not.
Another thing worth noting is that this result is actually the Dirac delta wave function peaking at R projected into the lowest Landau level. This was actually my first idea to solve the problem. I was like: well, isn’t the Dirac delta the smallest possible wave packet by all means? If the basis is complete, I can surely combine them into a Dirac delta, and it would be very easy to work out ak in this case. Then, I was like: nah, merely a single Landau level is not complete, so I cannot do that anyway. I then did not even bother to proceed with this approach and went on to trying other methods. It turns out that this approach is actually correct—at least it gives the same result as the correct approach.
]]>UlyssesZhanulysseszhan@gmail.comRegularizing the partition function of a hydrogen atom2024-06-30T21:18:12-07:002024-06-30T21:18:12-07:00https://ulysseszh.github.io/physics/2024/06/30/regularize-hydrogenIntroduction
The unit system
The unit system used in this article is Hartree atomic units: me=kB=ℏ=4πε0=e=1, where me is the electron mass.
In this unit system, the Bohr radius is aB=1, which is of angstrom order. Therefore, I will use 1010 as the order of macroscopic lengths. The Rydberg unit of energy is Ry=1/2, which is of electronvolt order. Therefore, I will use 103 as the order of inverse room temperature.
One can adjust the units to get results for the cases of other hydrogen-like atoms: use Z2/4πε0=1 instead of 4πε0=1, where Z is the atomic number.
In this article, I also assume that the mass of the nucleus is infinite. If you want more accuracy, you can use mNme/(mN+me)=1 instead of me=1, where mN is the mass of the nucleus.
Terminology about temperatures
I will mainly be working with the inverse temperature β:=1/kBT, where T is the temperature. However, I will still use “temperature” often to give some physical intuition. To avoid confusion in the context of using β and in appearance of negative temperature, I would avoid using phrases like “high temperature” and “low temperature”. Instead, here are some terminologies that I am going to use:
“Cold (positive) temperature” means β→+∞.
“Hot positive temperature” means β→0+.
“Cold negative temperature” means β→0−.
“Hot negative temperature” means β→−∞.
The energy levels of a hydrogen atom are (ignoring fine structures etc.) En=−1/2n2, with each energy level labeled by n∈Z+, and each energy level has gn:=n2 degeneracy (ignoring spin degeneracy, which merely contributes to an overall factor of the partition function). The partition function is Z(β):=n=1∑∞gne−βEn=n=1∑∞n2eβ/2n2,(1) which diverges for any β∈C (of course, normally we can only have β∈R, but the point of saying that it diverges for any complex β is that there is no way we can analytically continue the function to get a finite result). Does this mean that statistical mechanics breaks down for this system? Not necessarily. Actually, there are multiple ways we can tackle this divergence.
One should notice that, although this article concentrates on regularizing partition functions and that of the hydrogen atom in particular, all the methods are valid for more general divergent sums.
Here is a sentence that is quoted by many literatures on diverging series, so I want to quote it, too:
Divergente Rækker er i det Hele noget Fandenskap, og det er en Skam at man vover at grunde nogen Demonstrasjon derpaa.
—N. H. Abel
It translates to “Divergent series are in general deadly, and it is shameful that anyone dare to base any proof on them.”
The physical answer
A physicist always tell you that one should not be afraid of infinities. Instead, one should look at where the infinity comes out from the seemingly physical model, where there is something sneakily unphysical which ultimately leads to this unphysical divergence. In our case, the divergence comes from high energy levels. It is then a good time to question whether those high energy levels are physical.
There is a radius associated with each energy level in the sense of the Bohr model: rn=n2. When rn∼L:=1010 (which happens at n∼Λ:=105), the orbit is really microscopic now, and the interaction between the electron and the “box” that contains the whole experimental setup is now having significant effects. Or, if there is not a box at all, we can use the size of the universe instead, which is about rn∼L:=1036 (Λ:=1018). Use the model of particle in a box for energy levels higher than
n=Λ, and we have Z=n=1∑Λn2eβ/2n2+nx,ny,nz=1∑∞exp(−β2L2(nx2+ny2+nz2)π2),
where L is the side length of the box (assuming that the box is cubic). If L is very large, we can approximate the second term as a spherically symmetric integral over the first octant to get L3(2πβ)−3/2.
The integral approximation
This is actually the result for Boltzmann ideal gas, so it should be familar, but I still write down the calculation here for completeness.
We can approximate nx,ny,nz=1∑∞exp(−β2L2(nx2+ny2+nz2)π2)≈I:=∫0∞d3nexp(−β2L2(nx2+ny2+nz2)π2),
where ∫0∞d3n means ∫0∞∫0∞∫0∞dnxdnydnz. We can then change the integral to spherical coordinates: I=∫0∞814πn2dnexp(−β2L2n2π2)=4π2β3/2L3∫−∞∞dnn2e−n2/2,
where the factor of 1/8 is because we only integrate in the first octant, and the second step utilizes the symmetry of the integrand and redefines the integrated variable. This integral is than a familiar Gaussian integral of order unity. The value of it is not important for later discussion because all the arguments that follow only uses orders of magnitude, but I tell you it is 2π, which can be evaluated by integrating by parts once and utilizing the famous ∫−∞∞e−n2/2dn=2π. The final result is I=L3(2πβ)−3/2.
Is this an overestimation or underestimation? It is actually an overestimation. Draw a picture of e−n2/2 to convince yourself of this. We do not need to estimate how large the error is, though, because we will see that we only need an upper bound to get the arguments we need.
For the first term, we need to consider how the magnitude of the summand changes with n. The minimum value of the summand is at n=β/2. At room temperature, we have β∼103, so β/2 is well between 1 and Λ. Therefore, the largest term is either n=1 or n=Λ. The former is eβ/2, which is of order 10217, while the latter is Λ2, which is of order 1036 for the case of the size of the universe. We may then be interested in the n=2 term 4eβ/8, which is of order 1054. This is much larger than the n=Λ term but much smaller than the n=1 term, so it is second largest term in the sum.
An upper bound of the summation is given by replacing every term except the largest term by the second largest term, which gives Z<10217eβ/2+1072(Λ−1)4eβ/8+1048L3(2πβ)−3/2≈eβ/2. Therefore, the n=1 term dominates the entire partition function. This means that the hydrogen atom is extremely likely to be in the ground state (despite the seeming divergence of the partition function). This is intuitive. The probability of the system not being in the ground state is of order 10−55 for the size of the universe and 10−158 for a typical macroscopic experiment.
More accurate considerations
The usage of the model of particle in a box for energy levels n>Λ gives good enough arguments and results, but one may want to question whether this is appropriate.
What happens if you actually put a hydrogen atom in a box (for simplicity, make the box spherically symmetric)? More accurately, consider the quantum mechanical problem in spherically symmetric potential V such that V∼−r−1 for small r but grows fast and high enough at large r so that the partition function for bound states is convergent. This is called a confined hydrogen atom. A book chapter The Confined Hydrogen Atom Revisited discusses this problem in detail and cited several papers that did the calculations about the energy levels.
Cutoff regularization
By analyzing the orders of magnitude, we see that we actually do not lose much if we just simply cut off the sum at n=Λ. This corresponds to a regularization method called the simple cutoff: it replaces the infinite sum by a finite partial sum. This can be generalized a little by considering a more general cutoff function χ such that limx→0+χ(x)=1. Then, an infinite sum ∑n=1∞f(n) can be written as
n=1∑∞f(n)=λ→0+limn=1∑∞f(n)χ(λn). The simple cutoff is then the case where χ(x):=θ(1−x) and λ:=1/Λ, where θ is the Heaviside step function. For converging series, this gives the same result as the original sum thanks to the dominated convergence theorem.
For diverging series
For diverging series, this may give a finite result. For example, for f(n):=(−1)nnk, this method gives −η(−k) for any complex k and any smooth enough χ, where η is the Dirichlet eta function. Here is a check for the special case χ(x):=e−x (equivalent to the Abel summation). By definition of the polylogarithm, we have
n=1∑∞(−1)nnke−λn=Li−k(−e−λ). Now, substitute λ=0, and utilizing the identity Lis(−1)=−η(s), we have the result −η(−k).
You may wonder what is the case for f(n):=nk, which is also a diverging series, and it looks much like the case above. However, the limit at λ→0+ simply does not exist when Rek≥−1 (i.e., when the series diverges). This is because we have Lis(1)=ζ(s) only for Res>1, where ζ is the Riemann zeta function, but it is undefined for other values of s. If you analytically continue the result, you will get the famous Rieman zeta function.
However, although this series may converge for any positive λ, the limit as λ→0+ may not exist. If it diverges because f(n) grows too fast (or decays too slowly) as n→∞, then we should expect that the sum also tends to infinity as λ→0+. Assume that we can characterize this divergence by a Laurent series: n=1∑∞f(n)χ(λn)=k=−∞∑∞γkλk.(2) If the λ→0+ limit converge, we would expect γk<0 to be zero, and then the result is simply γ0. Therefore, we may also want only γ0 when the limit does not exist. To pick out
γ0, utilize the residue theorem: n=1∑∞f(n)=2πi1∮λdλn=1∑∞f(n)χ(λn),(3) where the domain of λ is now analytically continued from R+ to a deleted neighborhood of 0. Equation 3 is then a generalized version of Equation 2.
Notice that I have been super slippery in math in the discussion. For example, the Laurent series may not exist at all, and the analytic continuation may not be possible at all; even if they exist, the λ→0+ limit may also be different from γ0. However, I may claim that we should be able to select smooth enough χ for all of these to work, and the results will be independent of the choice of χ as long as Equation 3 works in this form.
Particularly, one can rigorously prove that for f(n):=nk, the sum obtained by this precedure is ζ(−k), where ζ is the Riemann zeta function, as long as xkχ(x) has bounded (k+2)th derivative and the sum converges. This is proven in an interesting blog article.
Alternative forms of cutoff regularization
In some cases, one may discover that ∑nf(n)χ(λn) is not analytic when λ→0+ so that the Laurent series expansion is not possible. An example is En:=lnlnn (for n≥2) with no degeneracies (this system also has a diverging partition function for any complex β). In this case, if you try to use the cutoff function χ(x):=e−x, the sum goes like (−lnλ)−β/λ instead of analytically when
λ→0+. Proving this is simple. We have Zλ=n=2∑∞e−λn(lnn)−β≈∫2∞e−λn(lnn)−βdn=λ(−lnλ)β1∫2λ∞(1−lnx/lnλ)βe−xdx,
where the last step uses the substitution x:=λn. Using the binomial theorem, we have Zλ≈λ(−lnλ)β1∫2λ∞dxe−xk=0∑∞(k−β)(−lnλlnx)k, where (k−β) is the binomial coefficient. Note that
Γ(k)(z)=∫0∞xk−1(lnx)ke−zxdx, where Γ(k) is the kth derivative to the Euler Gamma function, so the integral for x gives a factor Γ(k)(1) in the limit of λ→0+. Therefore,
Zλ≈λ(−lnλ)β1, where only the k=0 term in the sum is retained for the leading contribution as λ→0+.
However, for any k∈Z+, one can always choose functions h,χ so that the sum ∑nf(n)χ(λh(n)) goes like λ−k as λ→0+. For example, for χ(x):=e−x (equivalent to the Abelian mean or the heat-kernel regularization), we have
Zλ≈∫n0∞e−λh(n)f(n)dn=∫λf(n0)∞e−xf(h−1(λx))λh′(h−1(λx))dx.
We can choose h(n):=(∫f(n)dn)1/k so that
f(h−1(λx))=k(λx)k−1h′(h−1(λx)). Therefore, as λ→0+, we have
Zλ≈λ1∫λf(n0)∞e−xk(λx)k−1dx≈λkk!. However, this does not guarantee that the Laurent series expansion exists. This is a good trial, though. My math capacity does not allow me to confirm whether this is the case for the example of
En:=lnlnn.
Regularizing the hydrogen atom
After saying so much about cutoff regularization in general, what does it say about the partition function of a hydrogen atom? Try multiplying the cutoff function χ(λn) to the summand in Equation 1: Zλ:=n=1∑∞n2eβ/2n2χ(λn)=k=0∑∞k!(β/2)kn=1∑∞n2−2kχ(λn)→k=0∑∞k!(β/2)kζ(2k−2),(4) where the last step utilizes the result for f(n):=nk, with which we get rid of the dependence on λ. The last expression is then identified as Z.
Now that we get the expression of Z, we can get some useful things. However, this time we cannot simply use the summand divided by Z to get the probability of each energy level because that will break the normalization of the probability distribution. What we can do, however, is to find the expectation value of the energy using ⟨E⟩=−dlnZ/dβ. On the other hand, we have ⟨E⟩≤p1E1+(1−p1)E∞=−p1/2, so the probability 1−p1 that the system is not in the ground state is bounded above by 2⟨E⟩+1.
The first check to do is to verify that this result is consistent with the known behavior of the system at cold zero temperature, where the system is almost certainly in the ground state; in other words, limβ→+∞⟨E⟩=−1/2. To get Z for large β, we notice that ζ(+∞)=1, so Z≈eβ/2, and this leads to ⟨E⟩≈−1/2 as expected.
Now, we may try to estimate ⟨E⟩ for finite but large β (e.g., β=103) and thus give an upper bound for 1−p1. We can study the asymptotic behavior of ⟨E⟩ for cold positive temperature. It turns out that 1−p1≈3e−3β/8, which is 10−163 for β=103. As we can see, without any physical arguments but only with regularization, we get a result that seems sensible and well between the results in the last section for a hydrogen atom confined in a box with a typical macroscopic size or the size of the universe.
Derivation of the asymptotic behavior at cold positive temperature
We have Z=k=0∑∞k!(β/2)kζ(2k−2),dβdZ=21k=0∑∞k!(β/2)kζ(2k). Therefore, Z−2dβdZ=k=0∑∞k!(β/2)k(ζ(2k−2)−ζ(2k)). We can try to find the asymptotic behavior of the coefficient of each term. We have ζ(2k−2)−ζ(2k)=n=1∑∞(n2k−21−n2k1)=n=1∑∞n2kn2−1=22k3+O(32k1).
We also have ζ(2k−2)=1+O(2−2k), of course. Therefore, 1−p1≤2⟨E⟩+1=ZZ−2dZ/dβ=∑kk!(β/2)k(1+O(22k1))∑kk!(β/2)k(22k3+O(32k1)).
These power series are then simply exponential functions. Therefore, 1−p1≤eβ/2+O(eβ/8)3eβ/8+O(eβ/18)=3e−3β/8+O(e−4β/9).(5)
Although the asymptotic behavior at cold temperature (β→+∞) looks good, its behavior is very wrong at some regimes. At some temperature, the monoticity of ⟨E⟩ reverts, and then it gets even lower than the ground state energy −1/2 and heads all the way to −∞ at some finite temperature.This is clearly unphysical. This suggests that it is wrong to use the regularized result.
Plots
Here is a plot that shows how ⟨E⟩ starts to decrease with temperature at some point and becomes even lower than the ground state energy:
Plot of ⟨E⟩ vs. β
Here is a plot that shows how ⟨E⟩ goes to infinity at different temperatures:
Plot of ⟨E⟩ vs. β
Here are also plots for Z and dZ/dβ, if you are curious:
Plot of Z and dZ/dβ vs. β
The two vertical asymptotes of ⟨E⟩ corresponds to the two zeros of Z, which are β=0 and β=1.0721. It also has a zero, correponding to the zero of dZ/dβ at β=0.5530. The point where ⟨E⟩=−1/2 is β=11.2486, and the point where ⟨E⟩ has a local maximum is β=13.8021.
Another aspect where we can see that this result is wrong is that, if we look at the hot negative temperature limit β→−∞, although we have ⟨E⟩→0=supnEn as expected, it is approaching from the wrong side. In fact, because Z>0 while dZ/dβ<0 for β<0, we have ⟨E⟩>0 for β<0, exceeding the supremum of the energy levels, which is unphysical.
Derivation of the hot negative temperature limit
Here is a non-rigorous derivation. We can rewrite the regularized Z in a similar form as Z=−4β+n=1∑∞n2(eβ/2n2−1−2n2β)=N→∞lim(−(41+2N)β−61N(1+N)(1+2N)+n=1∑Nn2eβ/2n2).
For finite N, it has a straight line asymptote as β→−∞. The envelope of this family of straight lines (parametrized by N) is Z=(1−6β)3/2/363, which means that Z∼(−β)3/2 as β→−∞, where “∼” means that the ratio of the two sides approaches a positive constant. Similarly, we have dZ/dβ∼−(−β)1/2. Therefore, ⟨E⟩∼−β−1 as β→−∞.
Another regularization special to the hydrogen atom
Here is a special regularization method for the hydrogen atom which is not applicable to general systems. Consider the second derivative d2Z/dβ2 by differentiating the summand twice w.r.t. β in Equation 1, and then take twice antiderivative w.r.t. β. This gives Z=A+Bβ+k=0∑∞k!(β/2)kζ(2k−2)=A+Bβ+n=1∑∞n2(eβ/2n2−1−2n2β), where A,B are integration constants. The result from the cutoff regularization and
the zeta function regularization is simply A=0, B=−1/4. What is interesting about this is that it already determines the asymptotic behavior of 1−p1 at cold temperature, which is 1−p1≈3e−3β/8 (see Equation 5), no matter what A,B are.
Zeta function regularization
For a series ∑nf(n), if it diverges, we can instead consider ∑nf(n)−s for some s whose real part is big enough for the series to converge. Then, we can try to analytically continue to s=−1 to get a finite result for the original series. This is called the zeta function regularization.
When zeta function regularization fails
For the zeta function regularization to work, the asymptotic behavior of f(n) needs to be a non-trivial power law as n→+∞. Otherwise, the sum may not converge for any s. For example, consider En=lnlnn (with no degeneracies). The partition function with zeta function regularization is Zs:=n=2∑∞(lnn)βs. This series is divergent for any complex s.
A famous example is f(n):=n, which gives ∑nn=ζ(−1)=−1/12. Generally, for f(n):=nk, we have ∑nnk=ζ(−k). This is the same as the result for the simple cutoff regularization. This raises the question of whether the results obtained from those two methods are necessary the same whenever they both exist. I do not have a rigorous proof, but a strong argument is that both of them are the result of some analytic continuation, so they should be the same by the uniqueness of analytic continuation.
We can check this with the hydrogen atom. We have, for s>1/2 and β real, Zs:=n=1∑∞n−2se−sβ/2n2=k=0∑∞k!(−sβ/2)kn=1∑∞n−2s−2k=k=0∑∞k!(−sβ/2)kζ(2s+2k).
Analytically continue this result to s=−1, and then this gives the same result as Equation 4. The rest will be the same as the last section.
Can we trust this result?
However, can we trust this result, though? Everything is becoming fishy. Probabilities are no longer well-defined because how we normally derive them using Z is causing a divergent sum of probabilities and thus invalid. Yet somehow we are trying to estimate the bound of the probability of the system not being in the ground state and getting an expected result. You must have been feeling uncomfortable about this.
The first thing to ask is what we mean by “the expectation value” when the probability distribution is not even well-defined. If it means nothing physical, can we still trust its expression? The simple answer is no.
As we already see, although the result at cold temperature is sensible, the result at some regimes is clearly unphysical. We can also see similar problems with other systems. Consider the system that has energy levels En=lnn (with no degeneracies). We can easily get Z=∑nn−β=ζ(β), and thus there is a absi at β=1. For β>1, Z converges, and everything looks good. For β<1, the system is so hot that Z diverges. Previous arguments suggest that, in this region, the regularized Z is still ζ(β). However, we then have ⟨E⟩<0 in this region, which is lower than the ground state energy. This clearly should not be trusted.
In another aspect, we should note that since the estimation for 1−p1 does not depend on the size of the box confining the hydrogen atom, its rough agreement with the result in the last section should be considered a coincidence.
Another thing to note is that the result of the regularizations depend on whether we “flatten” the energy levels. We can “flatten” all the energy levels: pretend no degeneracies exist. For example, suppose a system with gn:=n and En:=n. However, we can rewrite the same system as En:=1,2,2,3,3,3,… (or equivalently En:=⌊2n+1/2⌋)1, with no degeneracies. This “re-grouping” of the energy levels can affect the result of regularizations and whether a zeta function regularization exists. For an immediate example, if we flatten the energy levels of the hydrogen atom, the zeta function regularization does not exist. Another simple example is that, for a system with En=const, we can essentially re-group the all-degenerate states to have any positive integer sequence gn to get very arbitrary results for the partition function.
Abscissa of convergence
Forget about the hydrogen atom, and let us consider a general system with (ever-increasing) energy levels En and degeneracies gn. For a given system, there is an abscissa of convergence βc, below (hotter than) which the partition function diverges. In other words, Z:=∑ngne−βEn converges for Reβ>βc and diverges for Reβ<βc. For most physical systems, we have
βc=0, meaning that it can have any positive temperature, which sounds sensible. The hydrogen atom has βc=+∞, and a two-level system has βc=−∞. A system with En=lnn and no degeneracy has βc=1.
The term “abscissa of convergence” is borrowed from the study of general Dirichlet series. The form of Z is indeed very much like a general Dirichlet series, but a general Dirichlet series requires E∞=+∞, which is not true for the hydrogen atom. However, the existence of an abscissa of convergence is still true for the more general case.
What does it mean physically to have an abscissa of convergence βc? First, if βc=−∞, then the system is well behaved at any temperature, which is good and does not need further care.
If ∣βc∣<∞, normally one should say the system cannot reach a certain temperature: the system can never be in equilibrium with a heat bath hotter than βc. Thermodynamically, one can say that the system needs to absorb an infinite amount of heat to reach this temperature. One can see this easily by considering any sensible system, which has βc=0: for β to go below zero means to make the temperature hotter than infinity, which of course needs an infinite amount of heat intuitively. One may want to see whether it is possible to regularize Z to get a finite result for Reβ<βc. A valid claim to make is that, if Z can be analytically continued to the half real axis to the left of βc, then any sensible regularization of Z there will give the same result as the analytic continuation. Actually, the analytic continuation is exactly the zeta function regularization if there is no degeneracy (or regarding degenerate states as different energy levels). However, it is possible that the analytic continuation does not exist. There may be a branch cut or a natural boundary. For example, if
En:=lnpn with no degeneracy, where pn is the nth prime number, then Z is the prime zeta function, which has a natural boundary at Reβ=0. Even if such a regularization exists, it should be questioned whether it is physical.
If βc=+∞, then the system is not well behaved at any temperature. This is the case for the hydrogen atom. Physically, this means that the system cannot be in equilibrium with a heat bath at any temperature. The problem with regularization is the same as the case with ∣βc∣<∞.
In a previous article about statistical ensembles, when I defined the partition function, I briefly mentioned that it is only defined for those intensive variables (β in the context of this article) such that the partition function converges. I did not talk about what to do with the partition function when it diverges, but what that article implied is that it is simply undefined and that no physical meaning should be assigned to it in principle. The existence of an abscissa of convergence tells us that there is a “hottest possible temperature” for any given system. The hydrogen atom is symply the case where the hottest possible temperature coincides with the coldest possible temperature (which is the absolute zero). For most sensible systems, the hottest possible temperature is just the positive hot limit. For systems such as En:=lnn, the hottest possible temperature is a finite positive temperature, which is at 3.16×105K, resulting from βc=1. This can be conterintuitive at first, but one should realize that it is not essentially different from the more common case of βc=0.
This is A002024 on OEIS. Coincidentally, the OEIS number of this sequence is the same as the year in which I am writing this article.↩︎
]]>UlyssesZhanulysseszhan@gmail.comLetting people know when you are asleep2024-02-21T02:26:45-08:002024-02-21T02:26:45-08:00https://ulysseszh.github.io/guide/2024/02/21/sleep-statusWhile I have been trying to respond whenever people reach out to me, it is impossible to be available 24/7 due to the simple fact that a human has to sleep to be alive. While this is annoying, it is also a fact that I cannot change.
Therefore, a natural idea that comes to my mind is to simply let people know when I am asleep so that they do not expect me to respond immediately.
Discord and GitHub have been among my most used platforms for some time, and they both have a feature to let users set a custom status (with a custom text and an emoji). This opens up a possibility of using a program to automatically set the status to indicate that I am asleep.
# Set sleeping status
gh user-status set'Sleeping...'--emoji='sleeping'--limited# Clear sleeping status
gh user-status set'null'--expiry=1s
Now, the next step is to run these commands automatically when I fall asleep and wake up. This can be done with MacroDroid, which can trigger actions based on various triggers. To run arbitrary commands, you can use the Tasker plugin for Termux. To have it working, one also needs to uncomment allow-external-apps = true in ~/.termux/termux.properties, and grant MacroDroid the permission to run Termux commands by
1
adb shell pm grant com.arlosoft.macrodroid com.termux.permission.RUN_COMMAND
MacroDroid supports using the return value of the sleep API to trigger an action, but this tends to be quite unreliable on my device. Therefore, I use it in conjunction with a quick setting tile that I can toggle manually. The macro has two triggers:
Fell Asleep / Woke Up (Android sleep API),
Quick Tile On/Off,
and it has these actions:
1
2
3
4
5
6
7
8
9
10
11
12
13
If Trigger Fired: Woke Up, or Quick Tile Off
If Sleeping = True
Clear sleeping status on Discord and GitHub
# Include other waking up logic here, such as turning off DND mode
End If
Sleeping = False
Else If Trigger Fired: Fell Asleep, or Quick Tile On
If Sleeping = False
Set GitHub and Discord user status to sleeping
# Include other falling asleep logic here, such as turning on DND mode
End If
Sleeping = True
End If
By the way, I have a bunch of topics that I want to write blog articles about, but I have been quite busy recently, so I may have to pause updating this blog for a while. I hope I can get back to writing soon!
]]>UlyssesZhanulysseszhan@gmail.comUsing nmcli to connect to eduroam in UCSB2024-01-08T01:03:36-08:002024-01-08T01:03:36-08:00https://ulysseszh.github.io/guide/2024/01/08/nmcli-eduroamSave this certificate to some file, say /YOUR/PATH/TO/ca.pem:
nmcli con mod eduroam 802-1x.eap peap
nmcli con mod eduroam 802-11-wireless-security.key-mgmt wpa-eap
nmcli con mod eduroam 802-11-wireless-security.proto rsn
nmcli con mod eduroam 802-11-wireless-security.pairwise ccmp
nmcli con mod eduroam 802-11-wireless-security.group ccmp,tkip
nmcli con mod eduroam 802-1x.ca-cert /YOUR/PATH/TO/ca.pem
nmcli con mod eduroam 802-1x.phase2-autheap mschapv2
nmcli con mod eduroam 802-1x.anonymous-identity anonymous@ucsb.edu
nmcli con mod eduroam 802-1x.identity YOUR_EDU_EMAIL_ADDRESS
nmcli con mod eduroam 802-1x.password YOUR_PASSWORD
Finally, you can connect to eduroam now!
This may also apply to eduroam in other campuses, but I haven’t tested it yet.
]]>UlyssesZhanulysseszhan@gmail.comThe duality between two plane trajectories related by a conformal map2023-12-22T11:19:04-08:002023-12-22T11:19:04-08:00https://ulysseszh.github.io/physics/2023/12/22/conformal-trajectoryI always feel amazed about how 2D physics can often be fascinating due to theorems in complex analysis. This article is about one among such cases.
Theorem. The conformal map w(z) transforms the trajectory with energy −B in potential U(z):=A∣dw/dz∣2 into the trajectory with energy −A in potential V(w):=B∣dz/dw∣2.
This result is pretty amazing in that it reveals a quite implicit duality between the two potentials, and it looks very symmetric as written.
This theorem, as I know of, was first introduced in the appendix of V. I. Arnold’s book Huygens and Barrow, Newton and Hooke. Part of this article is already covered in the relevant part of the book.
Power-law central-force potentials
Before I show the proof of it, let me first introduce it by a much more well-known example.
As we all know, Bertrand’s theorem states that the only two types of central-force potentials where all bound orbits are closed are U∝r−1 (the Kepler problem) and U∝r2 (the harmonic oscillator). How the two potentials are special among all sorts of different central-force potentials makes people wonder if there is any connection between them. Fortunately, there is one, and it is obvious once we notice that the complex squaring transforms any center-at-origin ellipses into focus-at-origin ellipses. Inspired by this, it is easy to see that trajectories in the Kepler problem can be transformed into trajectories of harmonic oscillators under complex squaring.
You may ask, how can we notice complex squaring does the said transformation on ellipses? The observation is noticing the simple algebra (z+z1)2=z2+z21+2, which means that the Joukowski transform z↦z+1/z of a unit circle simply translates under complex squaring. We can then try to generalize this to circles of other radii, whose Joukowski transformations are just ellipses! (If you remember, this is the second time Joukowski transformation appears in my blog. The first time was here.)
Then, are the Kepler problem and the harmonic oscillator the only two central-force potentials whose trajectories can be transformed into each other by a complex function? The answer is no. In fact, for any trajectory in almost any power-law central-force potential, we can take some power of it to get a trajectory in another power-law central-force potential.
This result can be summarized as follows. Taking the (α/2+1)th power of a trajectory with energy E in the potential U=arα (α=−2) gives a trajectory with energy F in the potential V=brβ, where
(α+2)(β+2)=4,b=−41(α+2)2E,F=−41(α+2)2a. To prove this, we just need to reparameterize the transformed trajectory in a new time coordinate τ defined as dτ=∣z∣αdt, where z is the complex position of the original trajectory. Then, by some calculation and utilizing the energy conservation, we can show that the parameter equation in terms of the new time coordinate satisfy the equation of motion we expect. I will not show the details here because they would be redundant once I prove the more general case using the same methods.
Corollaries and applications
There is an interesting special case, which is α=−2. There is no potential that is dual to U∝r−2. Another interesting case is α=−4, which is dual to itself (β=−4). It kind of means that the coefficient in the potential is “interchangeable” with the energy, and the trajectories can be derived from each other by taking the complex reciprocal.
We can get some interesting results with a=0, which is just the case of a free particle, whose trajectories are all straight lines. Since in this case we necessary have F=0, we can say that the zero-energy trajectory in any power-law potential is related to a straight line by a power. From this result, we can derive some interesting corollaries. For example, the zero-energy trajectory in the Kepler problem is a parabola (square of a straight line), which is well-known. The zero-energy trajectory in U∝−r−4 is a circle passing through the origin (reciprocal of a straight line), which is a pretty interesting not-so-well-known result.
Another interesting result is that, the deflection angle of an incident zero-energy particle scattered by the potential U∝−rα is θ under paraxial limit, if α=π−φ2φ,φ=±θ−2kπ,k∈N. This result can be easily derived by using the conformal transform of the real line (actually, a straight line that approaches the real line). The crucial part here is that k cannot take negative integers because we need α>−2. The reason is that, when α≤−2, paraxial zero-energy particles are bound to sink into the origin, and thus no scattering actually happens. This small pitfall indicates that the trajectory in the dual potential is not a two-side infinite straight line, either, in that limit, in contrast to being seemingly a free particle.
Some straightforward proofs
Let’s go back to the theorem I stated at the beginning of this article.
Proof. Consider a new time coordinate τ defined as dτ=∣dw/dz∣2dt. Then, the motion of w satisfies mdτ2d2w=mdτdtdtd(dτdtdtdw)=mdwdz2dtd(dwdz2dzdwdtdz)=mdwdz(dwdz)∗((dw2d2zdzdwdtdz)∗dtdz+(dwdz)∗dt2d2z).
Here we need to substitute d2z/dt2 by the equation of motion for z. By computing the real and imaginary parts separately, we can derive that for any holomorphic function f, the gradient of ∣f∣2 expressed as a complex number is ∇∣f∣2=2(df/dz)∗f. Therefore, the equation of motion for z is
mdt2d2z=−2Adzdw(dz2d2w)∗. According to series reversion, we have
d2w/dz2=−(dw/dz)3d2z/dw2. Therefore, the equation of motion for z can also be written as mdt2d2z=2Adzdw2(dzdw)∗2(dw2d2z)∗. Substitute this, and we have mdτ2d2w=dwdz(dw2d2z)∗(mdtdz2+2Adzdw2). Substitute the energy conservation of the motion of z: 21mdtdz2+Adzdw2=−B, and we have mdτ2d2w=−2Bdwdz(dw2d2z)∗, which is the equation of motion for w that we expect.
To get the energy of the motion of w, we calculate 21mdτdw2+Bdwdz2=21mdzdwdtdzdτdt2+Bdwdz2=dzdw2(−B−Adzdw2)dwdz4+Bdwdz2=−A, which is the energy conservation of the motion of w in the potential V that we expect. □
Noticing that we are only interested in the trajectory, we can just use Maupertuis’ principle to get a simpler proof.
Proof.S0=∫∣dz∣2m(−B−Adzdw2)=∫∣dw∣2m(−A−Bdwdz2). The abbreviated action is then exactly the same for the motion of z and the motion of w. Therefore, by Maupertuis’ principle, for any physical trajectory of z, the trajectory of w is also physical. □
Details worth noting
Invertibility of the conformal map
There are two different definitions of a conformal transformation in two dimensions. One is that a function defined on an open subset of C is conformal iff it is holomorphic and its derivative is nowhere zero. The other is that a function is conformal iff it is biholomorphic (is bijective and has a holomorphic inverse).
You may think here I have adopted the second definition because when I say V(w):=B∣dz/dw∣2, I am implicitly assuming that I can take the inverse of w(z) to get the function z(w) and then take the derivative of it. However, if that is the case, an immediate problem is that then the duality between the Kepler problem and the harmonic oscillator, from which I introduced the more general result in the first place, would not be actually covered by the “more general” result. This is because z↦z2 is not biholomorphic (because it is not injective).
Then, why did this never become a problem when we were studying the duality between the Kepler problem and the harmonic oscillator? All we have talked about is how we can derive a trajectory in the Kepler problem by squaring the trajectory of a harmonic oscillator, but we have not discussed about how we can reverse this process, as an essential part of the duality. You may think the reverse of the process would be totally natural given how symmetric our theorem is regarding the two potentials. However, the reverse is not actually well-defined since the inverse of squaring, i.e., taking the square root, is not a single-valued function. Nevertheless, it is still well-defined in some sense: starting with whichever branch we like, tracing one point on the trajectory of the Kepler problem, and moving it along this trajectory for two cycles, we will end up with a trajectory of the harmonic oscillator if we take the square root of the position and ensure we always choose the branch so that the mapping is continuously done.
What about other power-law central potentials? In those cases, we have non-closed trajectories, so we cannot just move along the trajectory for two cycles. For example, if we take w=z3, then the potential would be U=9A∣z∣4. For any non-closed trajectory, we can uniquely map it to a trajectory of the potential V=B∣w∣−4/3/9. However, we cannot uniquely do the reverse mapping. There would be three different trajectories in the potential U that can be mapped to the same trajectory in V, and we can in turn map the trajectory in V to any of the three trajectories in U depending on which branch we choose.
Therefore, to generalize this for more general potentials, we can use similar arguments. Because z↦w has non-zero derivative everywhere in our considered region, it is everywhere locally invertible by the Lagrange inversion theorem. We can then bijectively map the trajectories in the two dual potentials locally for every small (and finite) segment and then patch them together to get the global correspondence between the two trajectories. This mapping may not be well-defined globally, but the trajectories can still be considered dual to each other. If the potential also becomes multi-valued due to the mapping w↦z being multi-valued, then we should imagine this situation like this: at some point, the potential may be different when the particle visit here for the second time. This case does not happen if we only look at power-law potentials, but it does happen for more general cases.
What makes this sense of duality weaker is that one trajectory can be dual to multiple different trajectories. A case worth noting is that sometimes one trajectory can be mapped to infinitely many different trajectories. This happens when the trajectory runs around a logarithmic branch point. However, we can gain the sense of duality back if we can also consider the case where z↦w is multi-valued. The notion of conformal transformation is now too limited to cover this case, a better notion is a global analytic function, which generalizes the notion of analytic function to allow for multiple branches.
Requirements for the potential
Not any potential can be expressed as A∣dw/dz∣2. How can we determine whether a potential can be expressed in this form?
Theorem. A continuous potential U can be expressed in the form of A∣dw/dz∣2 (where w(z) is a conformal transformation) iff one of the following conditions is met:
U is zero everywhere, or
ln∣U∣ is a harmonic function on the domain of U.
Proof. First, prove the necessity.
An obvious requirement is that the potential must be positive everywhere or negative everywhere (or zero everywhere, but that is trivial). The sign is determined by the sign of A. Therefore, without loss of generality, we can assume A=1 because we can always absorb a factor of ∣A∣ into w and adjust the overall sign of U accordingly.
We can decompose (dw/dz)2 in the polar form (dw/dz)2=∣dw/dz∣2eiφ=Ueiφ, where φ is a real function of z. Applying the Cauchy–Riemann equations to (dw/dz)2 gives i∂x(dzdw)2=∂y(dzdw)2⟹i(eiφ∂xU+iUeiφ∂xφ)=eiφ∂yU+iUeiφ∂yφ.
Equate the real and imaginary parts, and we have {U∂xφ=−∂yU,U∂yφ=∂xU. Use the symmetry of second derivatives on φ, and we have ∂x∂yφ−∂y∂xφ=0⟹∂xU∂xU+∂yU∂yU=0. In the language of vector analysis, this is just ∇2lnU=0.
Considering the case where U is negative everywhere, we have that ln∣U∣ is a harmonic function.
Then, prove the sufficiency.
The case where U is zero everywhere is trivial. Otherwise, because ln∣U∣ is defined everywhere on the domain of U, we must have U is non-zero everywhere. Because U is continuous, we have U is either positive everywhere or negative everywhere.
Without loss of generality, assume U is positive everywhere. Let φ be the harmonic conjugate of lnU. Then, lnU+iφ is a holomorphic function. We can then define dzdw=Ueiφ/2, which is also a holomorphic function. □
From now on, we will call this requirement on U as being log-harmonic for obvious resons.
We should notice that whether U is log-harmonic does not respect that any potential can have an additive constant and still be essentially the same potential. An immediate example is that a function that is positive everywhere may be negative somewhere if we add a constant to it. We may then want to ask whether U can be log-harmonic if we allow it to be added an additive constant. It is easy to do this: we can just apply the same test to U+C, and see if there is some C that makes it work. To illustrate, solve the equation ∇2ln∣U+C∣=0 for C, and then see whether it is a constant over the whole complex plane.
A property of log-harmonic functions is that the product of two log-harmonic functions is also log-harmonic.
Trajectories that run out of the domain
Trajectories often run out of the domain of the potential. For example, in the discussions about power-law potentials before, though not emphasized, the origin is outside the domain of the potential because it is either a pole or a zero of dw/dz (except the trivial case where w is simply proportional to z). Another example that is rather overlooked is that unbound trajectories go to infinity while infinity is often not in the domain of the potential, either.
What need to take care of is that, when the trajectories run out of the domain, the trajectory is cut off there, and the rest of the trajectory is never considered (even if it may come back to the domain again later). Take the Kepler problem ane the harmonic oscillator as an example. If a trajectory of the harmonic oscillator passes through the origin, which is outside the domain, the trajectory degrades from a closed ellipse to a segment. If you take the square of a segment passing through the origin, you will get a broken line folded into itself, which looks like a particle in the Coulomb field may sink into the origin and then goes back along the exact path it came along. This would confusing if it were physical.
Arbitrariness in the construction of the conformal map
The construction of z↦w is not unique for a given U.
Rotation and translation
First, we can observe that the substitution w→w′:=weiθ+w0 does not change ∣dw/dz∣ (nor thus U). The real number θ is a function of z in principle, but if we want w to be holomorphic on a connected region, then θ must be a constant (except the trivial case where w=0).
The dual trajectory does change, though, but the dual potential V is also changed, too. Because ∣dz/dw′∣=∣dz/dw∣, we have V′(w′)=V(w)=V((w′−w0)e−iθ). Therefore, the dual trajectory and the dual potential are also rotated and translated by the same amount.
Scaling
Before introducing scaling, I need to add some words about the unit systems. In the above discussions, I have never mentioned what units or dimensions do z,w,A,B have. The natural way of thinking is to let z,w have the dimension of length and let A,B have the dimension of energy. However, this is not the only way of thinking. We will later see that the z-space and the w-space can have totally different dimensions.
The dimensions or units of variables in a physical formula can be totally different from what they were originally intended to be. For example, when a particle is rotating, its motion needs to satisfy r˙=ω×r, where ω is the angular velocity. However, although r has the dimension of length when it is first introduced, this formula is satisfied by any rotating vectors. A typical example is that the angular momentum changes according to this formula when a rigid body is doing precession. For another example, in classical mechanics and general relativity, the coordinates used to describe the motion of a particle are often not in the dimension of length, but have all sorts of dimensions. For another example that is less well-known, just because the Berry connection has the same gauge transformation as the electromagnetic potential, a bunch of formulas that are useful in electromagnetic theory can be applied to the Berry connection to define all sorts of interesting quantities with rich physical implications. The units of Berry connection are, however, very unimportant because they are literally arbitrary.
Therefore, what does a unit system actually bring us in a physical theory? The only thing it brings us is the ability to conveniently see in what aspects our theories are invariant under the scaling of some quantities. For example, in classical mechanics, we can scale the mass and the potential of any system with the same factor, and then the system will still behave the same in terms of the time-dependent length-based motion. This is because the part of the dimension of energy that is independent of length and time is to the first power of the dimension of mass. For similar reasons, we can derive another two scaling invariances, one about length-scaling and the other about time-scaling. In quantum mechanics, we suffer one less such scaling invariances because of the existence of ℏ; in special relativity, we suffer one less such scaling invariances because of the existence of c; and in general relativity, we suffer two less such scaling invariances because of the existence of G and c. This is the incentive of introducing natural units in physics: they give us a more clear image of how our theory can be scaled leaving the physics invariant.
As for dimensional analysis, the essence of it is to find the required form of theory so that it satisfies some sort of scaling invariance. For example, we can use dimensional analysis to derive that the frequency of a harmonic oscillator is proportional to the square root of the ratio of the stiffness to the mass. We know this must be correct because this is the only theory that is consistent with the three scaling invariances that must be satisfied by any theories under the framework of classical mechanics.
Now, consider the scaling in w, i.e., w→w′:=w/C for some non-zero real number C. The potential U can be kept invariant by scaling A→A′:=C2A. However, we cannot change B if we want to leave the trajectory of z unchanged because it is determined by the energy of the trajectory of z. Therefore, the dual potential V would be scaled to
V′(w′)=C2V(w)=C2V(Cw′). This means that physics is unchanged if length is scaled by C and energy and potential are both scaled by C2. This corresponds to one of the three scaling invariances in classical mechanics that we talked about before.
What is interesting here is that the length-scaling in the w-space is done independently of that in the z-space. This means that the length dimension in the two systems are independent of each other, so the two systems can have totally different unit systems.
Canonical transformation of time
The transformation from z to w seems like a coordinate transformation, which is covered by canonical transformations. However, here we have an additional requirement about the form of the Hamiltonian: H=2mpz2+U(z),K=2mpw2+V(w), where K is the transformed Hamiltonian (or called the Kamiltonian in the jargon of canonical transformations). This is not generally true because the transformation in the generalized momentum is restrictively determined when the transformation in the generalized coordinate is already given. From the proof of the original theorem, we can see that a transformation in time is a must, which is given by
dτ=∣dw/dz∣2dt.
The problem is that the canonical transformations covered in most textbooks usually do not allow for a transformation in time, but only for a transformation in the canonical variables. Therefore, I need to first address the problem of integrating the transformation of time into the theory of canonical transformations. I will not do this for the most general case, but only for the case general enough for the purpose of explaining the case interesting this article.
Change in the time variable in the stationary-action principle
Before diving into the general canonical transformation, let’s first consider the case where the transformation is only in the time variable.
Consider a system with the Lagrangian L(q,q˙) (not explicitly dependent on time). Then, the action can be expressed as S=∫t1t2L(q,q˙)dt. The same integral can be expressed in terms of a new time variable τ as
S=∫τ1τ2L(q,q˚τ˙)τ˙dτ, where q˚:=dq/dτ is the generalized velocity in the new time variable. The transformed Lagrangian, or what I want to call the Magrangian1, is then M(q,q˚):=L(q,q˚τ˙)τ˙1.(1) For the case that we are concerning, τ˙ is a positive real function of q but does not (explicitly) depend on t. The limits τ1,τ2 satisfy the condition
τ2−τ1=∫t1t2τ˙(q)dt. This relation is crucial. When finding the variation δS, we are fixing t1,t2. However, we cannot fix both τ1,τ2 because their difference is dependent on the path
q(t). What we can do is to fix τ1 and to let τ2 have a variation given by δτ2=∫t1t2τ˙′(q)δqdt=∫τ1τ2τ˙(q)τ˙′(q)δqdτ,
where τ˙′ is the derivative (or gradient, in higher dimensions) of τ˙ as a function of q. As can be seen, only if τ˙ is a constant (i.e., τ is simply an affine transform of t) does δτ2 vanish for any δq.
Using the well-known variation of the action when there is variation in the time coordinate, we have δS=∫τ1τ2(∂q∂M−dτd∂q˚∂M)δqdt−K(q(τ2),q˚(τ2))δτ2,
where K(q,q˚):=q˚∂q˚∂M−M is the energy (or the Kamiltonian, but as a function of generalized coordinates and velocities) of the system.
A quick check of this variation
Because q(τ2) is fixed, we have q(τ2)=q(τ2+δτ2)+δq(τ2+δτ2)=q(τ2)+q˚(τ2)δτ2+δq(τ2)⟹δq(τ2)=−q˚(τ2)δτ2.
Now, calculate the variation of the action: δS=∫τ1τ2(∂q∂Mδq+∂q˚∂Mδq˚)dτ+M(q(τ2),q˚(τ2))δτ2.
Recall the derivation of the Euler–Lagrange equation. For the second term in the integrand, we can integrate by parts to get ∫τ1τ2∂q˚∂Mδq˚dτ=∂q˚∂Mδqτ1τ2−∫τ1τ2dτd∂q˚∂Mδqdτ=−∂q˚∂Mq˚τ2δτ2−∫τ1τ2dτd∂q˚∂Mδqdτ. Substitute this back into the expression for δS, and we have the desired result.
If we let the first term in δS vanish, we would get the well-known Euler–Lagrange equation:
∂q∂M−dτd∂q˚∂M=0.(2)
However, that term is not zero because there is another term in δS. If we want the Euler–Lagrange equation to be satisfied, we need the second term to be zero. This means that either K is zero or δτ2 is zero. The latter case will lead us to the trivial case because we have just derived that δτ2 is zero only if τ˙ is a constant. The former case can be satisfied, however. If the Euler–Lagrange equation is satisfied, then K is a conserved quantity due to the symmetry of M in τ-translation. Then, if K happens to be zero at some point, it will be zero over the whole motion, and the stationary-action principle will be satisfied by the motion between any two points.
We can explicitly show that Equation 2 can be derived from the original Euler–Lagrange equation under the zero-energy condition.
Proof. We need to first derive the condition of zero energy in the old time variable. Take derivatives of Equation 1 with respect to q˚, and we have ∂q˚∂M=∂q˙∂Lτ˙τ˙1=∂q˙∂L. Therefore, the Kamiltonian is K=∂q˚∂Mq˚−M=∂q˙∂Lτ˙q˙−τ˙L=τ˙H,(3) where H:=q˙∂L/∂q˙−L is the original Hamiltonian. This relation means that the condition K=0 is equivalent to the condition H=0.
Then, use Equation 1 to explicitly calculate the lhs of Equation 2: ∂q∂M−dτd∂q˚∂M=(∂q∂L+∂q˙∂Lq˚τ˙′(q))τ˙(q)1−Lτ˙(q)2τ˙′(q)−τ˙(q)1dtd∂q˙∂L=(∂q∂L−dtd∂q˙∂L)τ˙(q)1+(∂q˙∂Lq˙−L)τ˙(q)2τ˙′(q)=0.□
Specifying τ vs. specifying τ˙
We will see that specifying τ˙, which is what we have done in the above discussion, is pretty different from specifying τ. The latter is much simpler, but the former is the one that is used for the conformal duality between potentials. Although I do not have to discuss what the transformation should look like when we specify τ instead of τ˙, I will still do this because I need to point it out that it is quite different from the case we have discussed.
Recall that the canonical transformation is just a transformation of coordinates in the phase space that preserves the canonical one-form up to a total differential. Adding the idea of time transformation into this has a difficulty that time is not a coordinate in the phase space. Including the time coordinate, the actual one-form that needs to be preserved is dS=pdq−Hdt, which is exactly the total differential of the action. Therefore, we have pdq−Hdt=PdQ−Kdτ+dG,(4) where P,Q are the new canonical variables, K is the transformed Hamiltonian, and G is called the generating function of the canonical transformation. Assume τ and G are both functions of q,Q,t. Then, we have
pdq−Hdt=PdQ−K(∂q∂τdq+∂Q∂τdQ+∂t∂τdt)+∂q∂Gdq+∂Q∂GdQ+∂t∂Gdt. Compare the coefficients of
dq,dQ,dt on both sides, and we have p+K∂q∂τ−∂q∂G=0,P−K∂Q∂τ+∂Q∂G=0,H−K∂t∂τ+∂t∂G=0.(5) These equations determines
Q,P,K. They will satisfy Hamilton’s equation: dτdQ=∂P∂K,dτdP=−∂Q∂K.
An example
Consider the Hamiltonian H=p+q. The motion is q=q0+t,p=p0−t. Consider the new time variable τ=t/q and the generating function G=Qq. With Equation 5 and the expression for H and τ, we have a set of five equations: ⎩⎨⎧p−Kq21t−Q=0,P+q=0,H−Kq1=0,τ=qt,H=p+q⟹⎩⎨⎧q=−P,p=1−τQ−Pτ,K=1−τ(P−Q)P,t=−Pτ,H=1−τQ−P.
With the expression for the Kamiltonian K, we get the motion of Q,P: Q=1−τ(2−τ)τP0+(1−τ)Q0,P=1−τP0. This is consistent with the motion of q,p as can be verified with calculation.
It seems that specifying τ is much easier than specifying τ˙. We can easily discuss the most general case and perfectly recover the equation of motion without having to impose a bizarre condition like the zero energy. This is because specifying τ˙ is, in some sense, more general than specifying τ: we can always find the total derivative of τ for any form of it, but we cannot always find τ given the form of τ˙ because of limitations on the integrability.
The conformal transformation as a canonical transformation
Now, we can discuss the conformal transformation as a canonical transformation. The procedure is pretty analogous to that in the previous section, but this time the conclusion would only be valid under the zero-energy condition.
Denote the real and imaginary parts of z as x,y, and the real and imaginary parts of w as X,Y. The Cauchy–Riemann equations give u:=∂x∂X=∂y∂Y,v:=∂y∂X=−∂x∂Y. Here u,v are two real functions defined for convenience. They can either be functions of x,y or functions of X,Y, depending on which are more convenient. With u,v, we have
dX=udx+vdy,dY=−vdx+udy, The time transformation is given by τ˙=dzdw2=u2+v2. The original Hamiltonian is H=2mpx2+py2+A(u2+v2)+B (the last term is added because we want it to be zero during the motion). Substitute these into Equation 4, and we have (dG=0)
=pxdx+pydy−(2mpx2+py2+A(u2+v2)+B)dtPX(udx+vdy)+PY(−vdx+udy)−K(u2+v2)dt.
Then, after some calculations, we have perfectly the expected result px=uPX−vPY,py=vPX+uPY,K=2mPX2+PY2+u2+v2B+A.
The condition K=0 specifies the energy of the dual trajectory.
For unknown reasons, the transformed Hamiltonian is called the Kamiltonian just because we often use the symbol K to represent it. However, there is not a similar convention for the transformed Lagrangian, so I would like to use the letter M and call it the Magrangian. The surname “Lagrange” is originated from the French phrase la grange (meaning “the barn”), and correspondingly “Magrange” may refer to the French phrase ma grange (meaning “my barn”). This pun then can make “Magrangian” kind of mean “my Lagrangian”.↩︎
]]>UlyssesZhanulysseszhan@gmail.comEmbed the latest Mastodon post in my website2023-11-19T13:51:36-08:002023-11-19T13:51:36-08:00https://ulysseszh.github.io/update/2023/11/19/embed-mastodonAs we all know you can embed a Twitter timeline in your website like this:
A Twitter timeline
Tweets by UlyssesZhan
This just embeds a specific Mastodon post instead of dynamically grabbing the latest posts. Also, this embed requires JavaScript on the client side, which I have been trying to avoid. Another downside of this embed is that it does not have a light-theme version.
The home page of my website shows my latest Mastodon post.
It should be rendered server-side, without the necessity of client-side JavaScript.
Blend the post in the webpage with a style consistent with rest of the webpage.
How do I ensure the embedded post is always the latest one if it was rendered server-side? This means I have to somehow trigger the building and deployment of by website automatically whenever a new Mastodon post is created. Thanks to the Huginn instance deployed on my self-hosted server, I can monitor my Mastodon account and trigger a GitHub Actions workflow whenever there is a new post.
Here is then the idea of implementing the roadmap:
Exercise 3.9. Show that five-fold rotation symmetry is inconsistent with lattice translation symmetry in 2D. Since 3D lattices can be formed by stacking 2D lattices, this conclusion holds in 3D as well.
Before I saw this problem, I had never thought about whether a plane lattice can have m-fold symmetry for any positive integer m. I was surprised at first that I cannot have a translationally symmetric lattice with 5-fold symmetry. After some thinking, I did realize that I cannot imagine a 5-fold symmetric plane lattice, so such a lattice cannot exist intuitively.
Actually, the only allowed rotational symmetries are 2-fold, 3-fold, 4-fold, and 6-fold. This result is known as the crystallographic restriction theorem. Then, how to prove it?
After jiggling around the possible structure of the symmetry group of a plane lattice, I finally proved it. I found that this proof is actually a simple and good example of how algebraic number theory can be used in physics.
Before dive into the proof, we need to first prove a simple lemma about real analysis:
Lemma 1. If G is a subgroup of (R2,+) that is discrete and spans R2, then there exist two linearly independent elements in R2 that generate G.
Proof. Because G spans R2, there exist two linearly independent elements g1,g2∈G.
Consider the vector subspace V1:=g1R and the subgroup G1:=G∩V1. Obviously, G1 should be generated by some element h1∈G1 (this is because V1≃R, and G1 as a discrete set must have a smallest positive element under that isomorphism, which must be the generator of
G0 because it would otherwise not be the smallest positive element). Therefore, G1=h1Z. Also, because h1=0, {h1,g2} must span R2.
Let T:={ah1+bg2∈G∣a∈[0,1),b∈[0,1]}. Then, T must be discrete (because G is) and bounded, and contains at least the element g2. Express every element in T as ah1+bg2 and pick out the one element with the smallest non-zero b, and denote it as
h2=a⋆h1+b⋆g2. Certainly, {h1,h2} span R2.
Now, for any g∈G, we can express it uniquely as g=ah1+bg2. Define c2:=⌊b⋆b⌋,c1:=⌊a−a⋆c2⌋,g′:=g−c1h1−c2h2. Then,
g′∈T, and if we express it as g′=a′h1+b′g2, then b′ is smaller than b⋆. By definition of b⋆, b′=0, so
g′∈G1. Hence, {h1,h2} generates G. □
Now, we are ready to prove our main result:
Theorem. There is a discrete subset of R2 that has both translational symmetry and m-fold symmetry iff φ(m)≤2, where φ is Euler’s totient function.
Proof. For the neccessity, prove by contradiction. I instead prove that a set that has the said symmetries must not be discrete.
Denote the plane as C. Assume that there is an m-fold symmetry around point 0. Then, for any lattice site z, the point Rz:=αz (where α:=e2πi/m) is also a lattice site. Assume that there is a translational symmetry with translation a, then the point Tz:=z+a is also a lattice site. Without loss of generality, we can adjust the orientation of our coordinate system and the length unit so that a=1.
The group G generated by {R,T} is a subgroup of the symmetry group of the lattice. Its action S:={g0∣g∈G} on the point 0 is a subset of all the lattice sites (this is only true when 0 is a lattice site; I will discuss later the other case). Notice that for any z∈S,n∈Z, we have TnRz=n+αz∈S. Therefore, by expanding any polynomial with integer coefficients using Horner’s rule, we can see that Z[α]⊆S.
Because α is an algebraic integer of degree φ(m) (the minimal polynomial of α is known as the mth cyclotomic polynomial), the generating set of Z[α] must have at least φ(m) elements. Therefore, according to Lemma 1, Z[α] is discrete iff φ(m)≤2.
For the case where 0 is not a lattice site, we can generate S by acting G on any lattice site z0. We can then easily prove that z0+Z[α]⊆S. To prove this, we just need to see that we can act R−k on z0 before further acting TnR on it for k times. All the other steps are the same and still valid.
For the sufficiency, because there are only finitely many m’s that satisfy φ(m)≤2. Therefore, we can enumerate these m’s and see that we can easily construct a plane lattice with both translational symmetry and m-fold symmetry for each m. □
I know the original problem in the book was probably not intended to be solved in this way, but it is really amazing how some seemingly purely mathematical areas can have their applications in physics, especially in an exercise problem of a physics textbook where pure mathematics is pretty unexpected.
Unfortunately, this proof, which is based on algebraic properties of certain complex numbers, does not generalize to higher dimensions because we cannot use the complex plane to represent a high-dimensional space.
]]>UlyssesZhanulysseszhan@gmail.comI restructured my blog2023-11-06T00:06:52-08:002023-11-06T00:06:52-08:00https://ulysseszh.github.io/update/2023/11/06/restructureRendering equations server-side
I have been using MathJax as a client-side equation renderer to render equations on my blog for a long time.
The main problem about the client-side rendering is that it makes people that turn off JavaScript on their browsers (e.g. for privacy reasons) unable to see the equations in my articles. Another problem is that it is annoying to wait for the browser to render all the equations, especially if the site owner could have rendered them for you.
I actually have had some experience in server-side equation rendering in Jekyll. In a past post, I talked about how I used Jekyll and KaTeX to render equations in emails server-side. For the website of Sunniesnow (see here for a related post), I use jekyll-katex to render the equations server-side.
Then, I thought, what is stopping me to render equations server-side on my blog? I then started the migration.
The painful building
The easiest way to switch to server-side equation rendering is just to use kramdown-math-katex. Install the gem, add an option math_engine: katex into the Kramdown configurations of _config.yml, add the needed CSS to the theme, and… What is my computer doing? It is just stuck at building the site!
By adding the --verbose option to the jekyll serve command, I can see what it was doing. I can see that it is never stuck on any step, but rendering each article that has equations (especially those with a ton of ones) takes seconds. Because I have dozens of articles with equations, it takes minutes to build the site. It seems that although KaTeX has always been advertising itself as the fastest math typesetting library for the web, it is not fast enough for me to use it to render equations server-side.
A way to mitigate this issue is to use the --incremental option of jekyll serve. This makes the building much faster except the first time. I can also expect Jekyll to support lazy building in the future, which will entirely skip the building phase and build the files as needed on the fly.
I found another way to partially mitigate this issue. On my blog, I have been extensively utilizing the markdownify filter to render Markdown inside the templates, including the title of the posts, the excerpt of the posts, and something else. Those are rendered in multiple places, including the homepage, the archive page, the RSS feed, and the search page. Since now rendering Markdown is being very slow, I decided to cache the rendered Markdowns. A very simple strategy is as follows:
Also, for most of the time I actually do not need to see the Markdown styling in the titles and excerpts, so I can also disable the markdownify filter depending on the site configuration, like this:
If I do not want to modify the site configuration file, I can also utilize an environment variable. I can use a after-init hook to set the configuration item based on the environment variable.
Rendering archives has also been very slow even with this Markdown disabling trick (for some reason I do not know). I decide to use another environment variable to disable the rendering of archives. Change the line gem 'jekyll-archives' in Gemfile to this:
By using --incremental and these two tricks together, I can finally build the site in seconds if I only modify one post during jekyll serve.
Cross-referencing
It seems that I cannot cross-reference equations using server-side means. First, KaTeX does not support cross-referencing, and the current workarounds are not acceptable for my use cases.
I then looked at kramdown-math-mathjaxnode, which uses the MathJax Node library to render equations server-side. The MathJax Node library itself does support rendering equation numbers, but kramdown-math-mathjaxnode does not support cross-referencing either. What is worse is that it has not been maintained for years, which means I probably had to rewrite the plugin myself, but I did not have spare time.
Even worse, Kramdown is just not suitable for implementing cross-referencing. I briefly looked at Kramdown’s source codes, and I realized that if I was about to write a math engine for Kramdown to support cross-reference, I would have to refactor Kramdown a bit. Actually, cross-referencing is quite a non-trivial feature for markup languages because of references that cannot be resolved during the first compilation. In LATEX, those references are resolved in the second compilation. I would need to refactor Kramdown to support a similar workflow to make it possible to implement cross-referencing.
Then, I looked at other Markdown engines. For Ruby, the only successful Markdown engine besides Kramdown that I know was Redcarpet (it used to be the default Markdown engine of Jekyll), and it was not designed with cross-referencing in mind either. Its developer even rejected to support math-related features a long time ago.
This is why I looked at non-Ruby Markdown engines. The first option that I came up with and also the option that I finally chose is Pandoc.
Pandoc is power in that its form of customization is filters, which transforms the whole parsed AST of the document. Because the whole AST is visible at once for a filter, it is then possible to implement cross-referencing by using a filter. Fortunately, someone has already written such a filter, and it is called pandoc-crossref. What is good about this approach is that it is independent of the math engine that I use: I can use MathJax or KaTeX, client-side or server-side, and it does not matter. The only drawback about it is that it does not support cross-reference a particular line in align or eqnarray environment, which is a feature that I have used in some of my posts. I have to reword those posts to avoid using that feature.
Now that we have a filter, we then need a way to let Pandoc render the math expressions server-side. Fortunately (again), someone has already written a filter for this purpose, and it is called pandoc-katex. Append this filter after the pandoc-crossref filter, and we are done.
The drawback about Pandoc is that it has no Ruby implementations, which means the only way to utilize Pandoc in Jekyll is to write a wrapper of it in Ruby and develop a Jekyll plugin for using that wrapper of Pandoc as the Markdown engine. Fortunately, someone has already done this: the wrapper is called pandoc-ruby, and the Jekyll plugin is called jekyll-pandoc.
Although the math rendering problem is solved, a somewhat unrelated problem arises: Pandoc does not use Rouge to highlight code blocks, but I like Rouge. Unfortunately, no one has written a Pandoc filter to use Rouge to highlight code blocks for me; but fortunately, I can write one myself quickly because it is easy enough, especially if I utilize Paru, which contains an API library to help me with writing Pandoc filters in Ruby.
Paru is actually an alternative to pandoc-ruby. Now that I also use Paru, I started to wonder if I should use pandoc-ruby at all. Considering that jekyll-pandoc has not been maintained for years, I decided to write my own Jekyll plugin to use Paru as the Markdown engine, and the simple plugin is called jekyll-paru.
Tedious work of reformatting the old posts
Using kramdown-math-katex is the only option that I do not need to adjust most of my posts. Another option, jekyll-katex, is not compatible with the markup that I use to write equations. I could not either just wrap the whole {{ content }} inside the {% katexmm %} block (due to some errors that I do not know), and the error messages then were impossible to utilize to help me locate the incompatibilities.
For the option that I finally use, Pandoc, I also have to adjust most of my posts. The major incompatibility is that I need to change all \label and \ref to the format recognizable by pandoc-crossref. Another incompatibility is that I need to use {target=_blank} instead of {:target="_blank"} to indicate a link to be opened in a new tab (as well as other HTML attributes that I use this syntax to embed in Markdown). Also, Pandoc does not allow blank lines inside math display blocks, which I have used in some of my posts (by the way, LATEX does not allow those blank lines either, which is pretty annoying).
I then wrote a simple script that use regular expressions to help me with this refactoring task. However, because of the diversity of the syntaxes that I used, I still need to check the posts manually after I ran the script. This makes the refactoring task still very tedious.
The much more complicated GitHub Actions workflow
Now, to build my site, the machine needs pandoc, pandoc-crossref, and pandoc-katex, none of which are Ruby Gems. I need to set up Haskell environment and Rust environment to install them. In GitHub Actions, I can use haskell-actions/setup to set up Haskell environment and cargo-install to install Cargo packages.
I do not know how I managed to make the GitHub Actions workflow file work expectedly at one shot, but I did.
Table of contents and searching
I have been using jekyll-toc to generate the table of contents for each post. The problem with using it now is that it strips the HTML in headings and only keeps the text, so headings with math expressions will not be rendered with nice math typesetting. It was not a problem previously because the client-side math rendering script will render the math expressions in the table of contents. Now that I switched to server-side math rendering, I had to patch jekyll-toc to make it work.
The search functionality was implemented by myself. It is a simple client-side searching powered by Lunr. I also had to refactor the search functionality a bit to make the search results be rendered with math expressions (which were previously also handled by the client-side math rendering script).
Updating the theme
The reason that I updated the theme is actually quite dramatic. This originated from me trying to use kramdown-math-katex. To ensure that the KaTeX CSS has the correct version with the KaTeX renderer used by katex-ruby, I decided to @import the SCSS file found in the repo of katex-ruby into my theme. I found that the SCSS file utilizes a function asset-path to load the fonts, but my CSS pre-processor does not support it, so I tried to extend my CSS pre-processor.
Jekyll uses jekyll-sass-converter to render CSS files, which once (v2) used sassc, but now (v3) uses sass-embedded. The former does not support extension of custom SCSS functions, but the latter does. Therefore, I need to upgrade my jekyll-sass-converter to v3. I actually could have upgraded it earlier because I have been using Jekyll v4 for a long time, but I deliberately kept using jekyll-sass-converter v2 because jekyll-action, which I used, had an issue about using sass-embedded. However, I have long ago migrated from jekyll-action to GitHub’s official upload-pages-artifact, so I can now upgrade jekyll-sass-converter to v3.
Then why does this have anything to do with the theme I used (which is Minima)? After I upgraded jekyll-sass-converter to v3, I found that there are some deprecation warnings in the SCSS files (they are actually already fixed, but I do not know why the issue is still open). This was also when I noticed that Minima has not released a new version for 4 years, and the last stable release is v2.5.1.
Then, how did I upgrade to Minima v3? I actually just tried to use the master branch of the Git repo of Minima, and I found that it was great.
Placeholder files for customization
I am glad to see Minima v3 introduced the include custom-head.html which allows for custom additional HTML metadata and the SCSS file minima/custom-variables.scss and minima/custom-styles.scss which allows for custom SCSS rules to override the default ones.
Although it took me some time to migrate my already present SCSS files and HTML metadata to the new structure, I am glad that Minima adopted this new structure that is more useful and more modern.
Skins
Another feature that I really like about Minima v3 is the support of skins. Minima now comes with several pre-defined skins which I can choose from. The default skin called classic is the one that originated from Minima v2, based on which I wrote my own skin.
I still remember a long time ago I tried to make my site support dark theme. It was such a pain because there are so many colors hardcoded in the theme so that I have to rewrite a large part of the SCSS files provided by Minima to support dark theme. Now, Minima v3 has a pre-defined skin called auto, which adaptively looks the same as classic or dark based on the browser’s prefers-color-scheme. I can now implement my skin based on auto (select my skin in the site’s configuration file and @import the auto skin in my skin’s SCSS file), and the codes are now much cleaner.